



Photo by timea dombi on Unsplash
Automate Documenting EventBridge Schemas in EventCatalog
Part 3 in a Series on Event Driven Documentation


In this series we're going to SUPERCHARGE developer experience by implementing Event Driven Documentation. In part 1 we used CDK to deploy EventCatalog to a custom domain using CloudFront and S3. In part 2 we used AWS Service Events from CloudFormation to detect when an API Gateway has deployed and export the OpenAPI spec from AWS to bundle it in our EventCatalog. In this post, we'll export the JSONSchema of EventBridge Events using schema discovery and bundle them into the EventCatalog.
🛑 Not sure where to start with CDK? See my CDK Crash Course on freeCodeCamp
The architecture we'll be deploying with CDK is:

In this part we'll focus on the final bit of architecture for subscribing to EventBridge Schema Registry Events and bootstrapping them into the EventCatalog. We'll also talk about strategies for integrating this into CI/CD to make it fully automated.
💻 The code for this series is published here: https://github.com/martzcodes/blog-event-driven-documentation
🤔 If you have any architecture or post questions/feedback... feel free to hit me up on Twitter @martzcodes.
EventBridge Schema Discovery
Amazon EventBridge offers a Schema Registry and Discovery feature. This feature monitors Event traffic and creates JSON Schemas based on the events it sees. The awesome thing about this is every time it creates a new schema or updates a new one... it emits an AWS Event that we can trigger off of! We'll use these events to export the discovered event's schema and bundle them in to EventCatalog, similar to how we did with API Gateways in part 2.
⚠️ If you have inconsistent Event Schemas (schemas with "optional" fields) a new version will be created every time the optional fields appear/disappear. A best practice for Event Schemas would be to make sure the event interfaces stay consistent (no optional fields and try not to use objects with changing keys).
Enabling Schema Discovery
First, we'll create a new construct for our Account Stack:
export interface EventsConstructProps {
bus: IEventBus;
specBucket: Bucket;
}
export class EventsConstruct extends Construct {
constructor(scope: Construct, id: string, props: EventsConstructProps) {
super(scope, id);
const { bus, specBucket } = props;
new CfnDiscoverer(this, `Discoverer`, {
sourceArn: bus.eventBusArn,
description: "Schema Discoverer",
crossAccount: false,
});
}
}
This construct uses CDK's level 1 construct called CfnDiscoverer. We provide it with our default bus and tell it not to track events that came from outside of the account we're currently in (that could get noisy).
🌈✨ Level 1 Constructs are 1:1 mappings with the equivalent CloudFormation(e.g. CloudFormation vs CDK L1)
Exporting Event Schemas
Creating the Infrastructure
With Schema Discovery enabled, we can create our lambda and invoke that lambda based on the AWS Service Events.
const eventsFn = new NodejsFunction(this, `eventsFn`, {
runtime: Runtime.NODEJS_16_X,
entry: join(__dirname, `./events-lambda.ts`),
logRetention: RetentionDays.ONE_DAY,
initialPolicy: [
new PolicyStatement({
effect: Effect.ALLOW,
actions: ["schemas:*"],
resources: ["*"],
}),
],
});
specBucket.grantReadWrite(eventsFn);
eventsFn.addEnvironment("SPEC_BUCKET", specBucket.bucketName);
bus.grantPutEventsTo(eventsFn);
We make sure to grant the lambda the right permissions (read/write to the bucket, the bucket name as an environment variable and putEvents to the default bus).
new Rule(this, `eventsRule`, {
eventBus: props.bus,
eventPattern: {
source: ["aws.schemas"],
detailType: ["Schema Created", "Schema Version Created"],
},
targets: [new LambdaFunction(eventsFn)],
});
AWS Schema events offer two detail types: "Schema Created" and "Schema Version Created". You can see the contents of these on the Explore page in the EventBridge console. We invoke our lambda using these detail types.
Processing the Events
Unlike Part 2... processing these events are a lot easier because we have everything we need via the Event and only need to make one aws-sdk call. The event includes the Schema Name and Version and we use that to export the JSONSchema via the aws sdk:
const RegistryName = event.detail!.RegistryName;
const SchemaName = event.detail!.SchemaName;
const SchemaVersion = event.detail!.Version;
const SchemaDate = event.detail!.CreationDate;
const exportSchemaCommand = new ExportSchemaCommand({
RegistryName,
SchemaName,
Type: "JSONSchemaDraft4",
});
const schemaResponse = await schemasClient.send(exportSchemaCommand);
From there we put it in our spec bucket:
const schema = JSON.parse(schemaResponse.Content);
const fileLoc = {
Bucket: process.env.SPEC_BUCKET,
Key: `events/${SchemaName}/spec.json`,
};
const putObjectCommand = new PutObjectCommand({
...fileLoc,
Body: JSON.stringify(schema),
});
await s3.send(putObjectCommand);
And emit the event with our presigned URL:
const getObjectCommand = new GetObjectCommand({
...fileLoc,
});
const url = await getSignedUrl(s3, getObjectCommand, { expiresIn: 60 * 60 });
const eventDetail: EventSchemaEvent = {
SchemaName,
SchemaVersion,
RegistryName,
SchemaDate,
url,
};
const putEvent = new PutEventsCommand({
Entries: [
{
Source,
DetailType: BlogDetailTypes.EVENT,
Detail: JSON.stringify(eventDetail),
},
],
});
await eb.send(putEvent);
Updating the Watcher to Copy the Schemas
In Part 2 we added a utility method to our spec construct that creates a lambda with a rule. We need to use that here to add a lambda for these Event schemas:
this.addRule({
detailType: BlogDetailTypes.EVENT,
lambdaName: `eventWatcher`,
});
This lambda simply copies the spec files using a certain S3 Key naming convention:
export const handler = async (
event: EventBridgeEvent<string, EventSchemaEvent>
) => {
const res = await fetch(event.detail.url);
const spec = (await res.json()) as Record<string, any>;
const fileLoc = {
Bucket: process.env.SPEC_BUCKET,
Key: `events/${event.account}/${event.detail.SchemaName}/${event.detail.SchemaVersion}.json`,
};
const putObjectCommand = new PutObjectCommand({
...fileLoc,
Body: JSON.stringify(spec, null, 2),
});
await s3.send(putObjectCommand);
};
Bootstrapping the Markdown files for EventCatalog
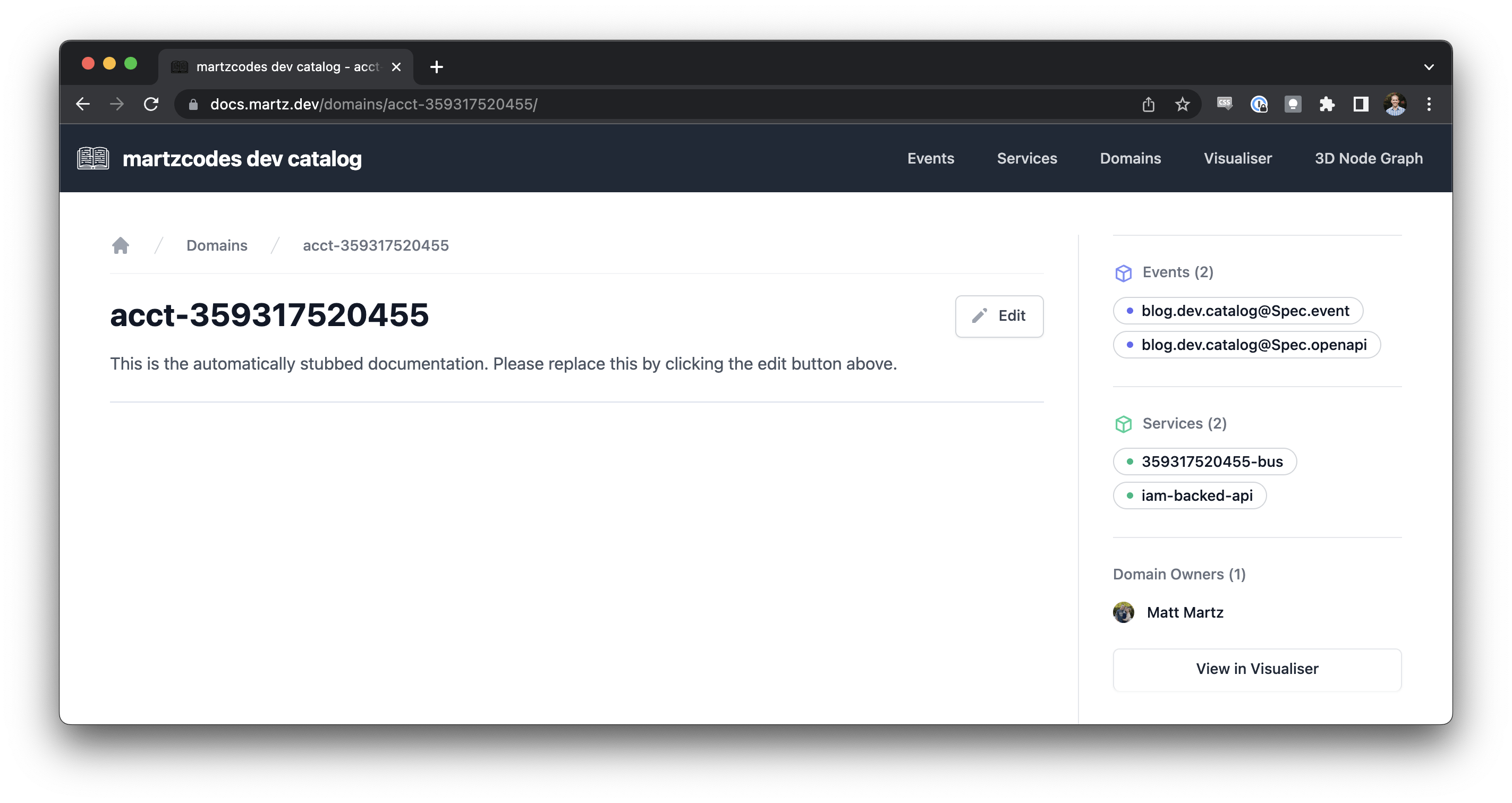
Now that we have our event JSONSchemas stored in our Watcher's Spec Bucket, we can update our prepare scripts to pull the files and bootstrap them (similar to how we did the API Gateway files in Part 2). One notable difference is that EventCatalog's Event interface offers "Consumers and Producers" and Event Versioning. We're going to create a pseudo-service that represents our Account's EventBus and specify that as the Producer for these events. This is kind of a hack, but it's a useful one. We're also going to create the files needed to version our events.
The folder structure for a domain will end up looking like this:
acct-<account>/
┣ events/
┃ ┣ blog.dev.catalog@Spec.event/
┃ ┃ ┣ index.md
┃ ┃ ┗ schema.json
┃ ┣ blog.dev.catalog@Spec.openapi/
┃ ┃ ┣ versioned/
┃ ┃ ┃ ┣ 1/
┃ ┃ ┃ ┃ ┣ changelog.md
┃ ┃ ┃ ┃ ┣ index.md
┃ ┃ ┃ ┃ ┗ schema.json
┃ ┃ ┃ ┗ 2/
┃ ┃ ┃ ┣ changelog.md
┃ ┃ ┃ ┣ index.md
┃ ┃ ┃ ┗ schema.json
┃ ┃ ┣ index.md
┃ ┃ ┗ schema.json
┣ services/
┃ ┣<account>-bus/
┃ ┃ ┣ index.md
┃ ┃ ┗ openapi.json
┃ ┗ iam-backed-api/
┃ ┣ index.md
┃ ┗ openapi.json
┗ index.md
Fetch the Events
To fetch the events we use aws-sdk's ListObjectsCommand to get the files prefixed with events/.
const listBucketObjectsCommand = new ListObjectsCommand({
Bucket,
Prefix: "events/",
});
const bucketObjects = await s3Client.send(listBucketObjectsCommand);
const specs = bucketObjects.Contents!.reduce((p, c) => {
const key: string = c.Key!;
const splitKey = key.split("/");
const account = splitKey[1];
const schemaName = splitKey[2];
const schemaVersion = splitKey[3].split(".")[0];
if (!Object.keys(p).includes(`${account}-${schemaName}`)) {
return {
...p,
[`${account}-${schemaName}`]: {
key,
account,
schemaName,
schemaVersion,
versions: [{ schemaVersion, key }],
},
};
}
p[`${account}-${schemaName}`].versions.push({ schemaVersion, key });
return p;
}, {} as Record<string, { key: string; account: string; schemaName: string; schemaVersion: string; versions: { schemaVersion: string; key: string }[] }>);
We store these S3 keys in an object so that we can determine the latest version of each spec, and we process them by schema.
const specKeys = Object.keys(specs);
for (let j = 0; j < specKeys.length; j++) {
const specMeta = specs[specKeys[j]];
const versionInfo = {
schemaVersion: 0,
key: "",
index: -1,
};
specMeta.versions.forEach((version, versionInd) => {
if (Number(version.schemaVersion) > versionInfo.schemaVersion) {
versionInfo.schemaVersion = Number(version.schemaVersion);
versionInfo.key = version.key;
versionInfo.index = versionInd;
}
});
if (versionInfo.index > -1) {
specMeta.key = versionInfo.key;
specMeta.schemaVersion = `latest`;
specMeta.versions.splice(versionInfo.index, 1);
}
const getSpecCommand = new GetObjectCommand({
Bucket,
Key: specMeta.key,
});
const specObj = await s3Client.send(getSpecCommand);
const spec = await streamToString(specObj.Body as Readable);
// ...
}
Ensure the Domain folder exists
In Part 2 we created a makeDomain shared method. To ensure the domain folder exists we just need to call it:
const domainPath = makeDomain(specMeta.account);
Create the Pseudo Bus Service
Next, we create the pseudo service:
const pseudoServiceName = `${specMeta.account}-bus`;
const pseudoServicePath = join(
domainPath,
`./services/${pseudoServiceName}`
);
mkdirSync(pseudoServicePath, { recursive: true });
const apiMd = [
`---`,
`name: ${pseudoServiceName}`,
`summary: |`,
` This is a pseudo-service that represents the Default Event Bus in the AWS Account. It isn't a real service.`,
`owners:`,
` - martzcodes`,
`badges:`,
` - content: EventBus`,
` backgroundColor: red`,
` textColor: red`,
`---`,
];
writeFileSync(join(pseudoServicePath, `./index.md`), apiMd.join("\n"));
Create the Events
We create the latest (parent) event:
const eventPath = join(domainPath, `./events/${specMeta.schemaName}`);
mkdirSync(eventPath, { recursive: true });
writeFileSync(join(eventPath, `./schema.json`), spec);
if (!existsSync(join(eventPath, `./index.md`))) {
const apiMd = [
`---`,
`name: ${specMeta.schemaName}`,
`version: latest`,
`summary: |`,
` This is the automatically stubbed documentation for the ${specMeta.schemaName} Event in the ${specMeta.account} AWS Account.`,
`producers:`,
` - ${pseudoServiceName}`,
`owners:`,
` - martzcodes`,
`---`,
``,
`<Schema />`,
];
writeFileSync(join(eventPath, `./index.md`), apiMd.join("\n"));
}
Add Versioning
And finally the version:
for (let k = 0; k < specMeta.versions.length; k++) {
const specMetaVersion = specMeta.versions[k];
const getSpecVersionCommand = new GetObjectCommand({
Bucket,
Key: specMeta.key,
});
const specVersionObj = await s3Client.send(getSpecVersionCommand);
const specVersion = await streamToString(
specVersionObj.Body as Readable
);
const versionPath = join(
eventPath,
`./versioned/${specMetaVersion.schemaVersion}`
);
mkdirSync(versionPath, { recursive: true });
writeFileSync(join(versionPath, `./schema.json`), specVersion);
const apiMd = [
`---`,
`name: ${specMeta.schemaName}`,
`version: ${specMetaVersion.schemaVersion}`,
`summary: |`,
` This is the automatically stubbed documentation for the ${specMeta.schemaName} Event in the ${specMeta.account} AWS Account. This is an old version of the spec.`,
`producers:`,
` - ${pseudoServiceName}`,
`owners:`,
` - martzcodes`,
`---`,
``,
`<Schema />`,
];
writeFileSync(join(versionPath, `./index.md`), apiMd.join("\n"));
const changelog = [`### Changes`];
writeFileSync(
join(versionPath, `./changelog.md`),
changelog.join("\n")
);
}
The Final Result
⚡️ You can see this in action at docs.martz.dev
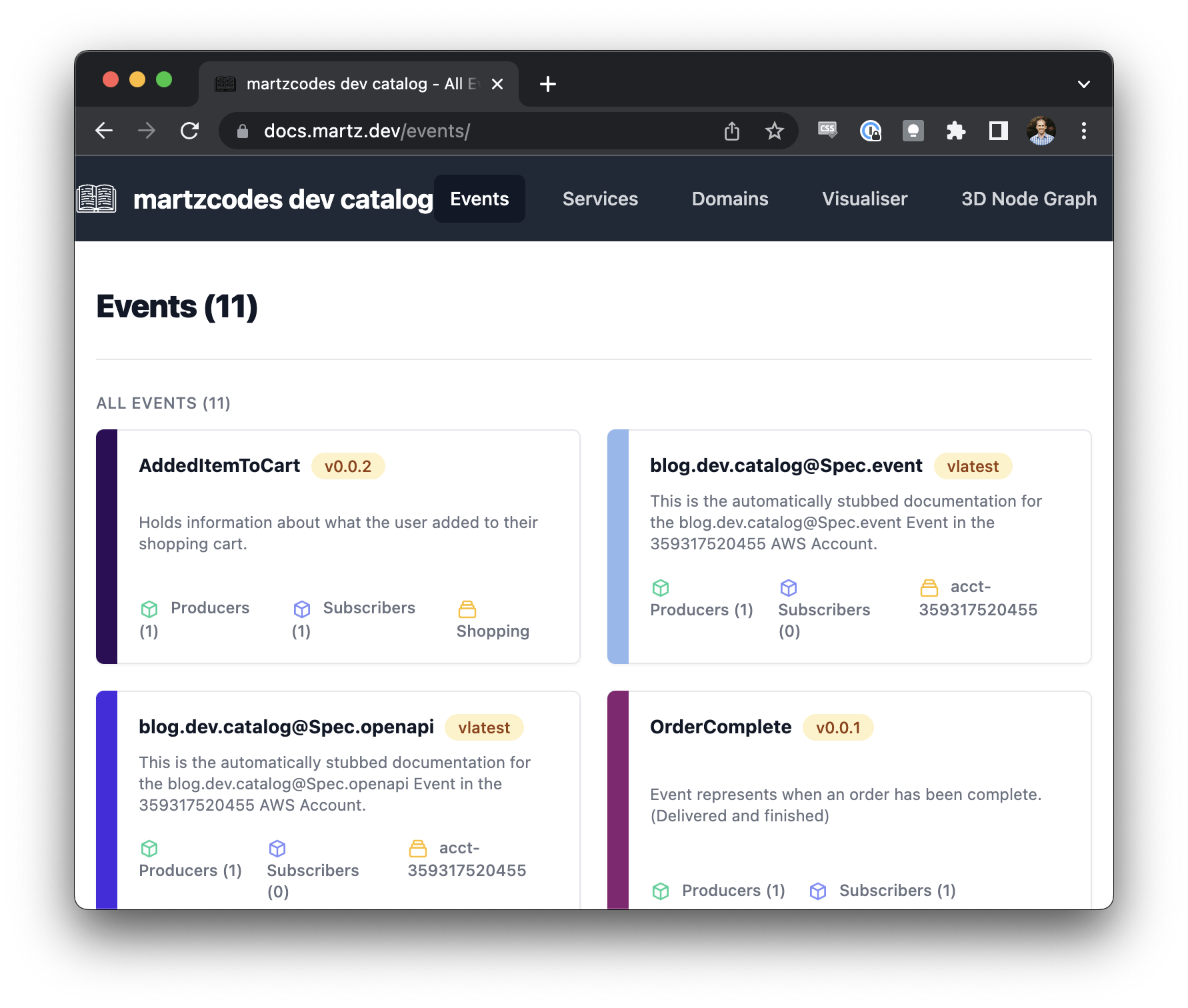
CI/CD Strategies
There are a few factors when determining your own CI/CD strategy for this. Right now everything is automatically updated when we do CDK deploys... but the CDK deploys themselves aren't automated.
The big factor is how many things are you tracking. At work we monitor 30+ AWS accounts used by > 100 developers. That runs the risk of being too much to do something like having the watched events kick off a deployment pipeline. Instead we'll likely use a scheduled CI/CD build to periodically update the documentation.
For CI/CD you could:
- Create a CodeBuild/CodePipeline project to automatically deploy the EventCatalog based on "watched" events.
- Connect your normal CI/CD up to a schedule (maybe you have a lot of events from many accounts and only want to update documentation every hour or so).
- Continue manually deploying it (which is what I'll do for my personal account since I don't deploy there often)
What's Next?
AWS Service Events offer a lot of useful insights in to your applications deployed to AWS.
💡Want to see what other Service Events are available? Check out the EventBridge "Explore" page in the console
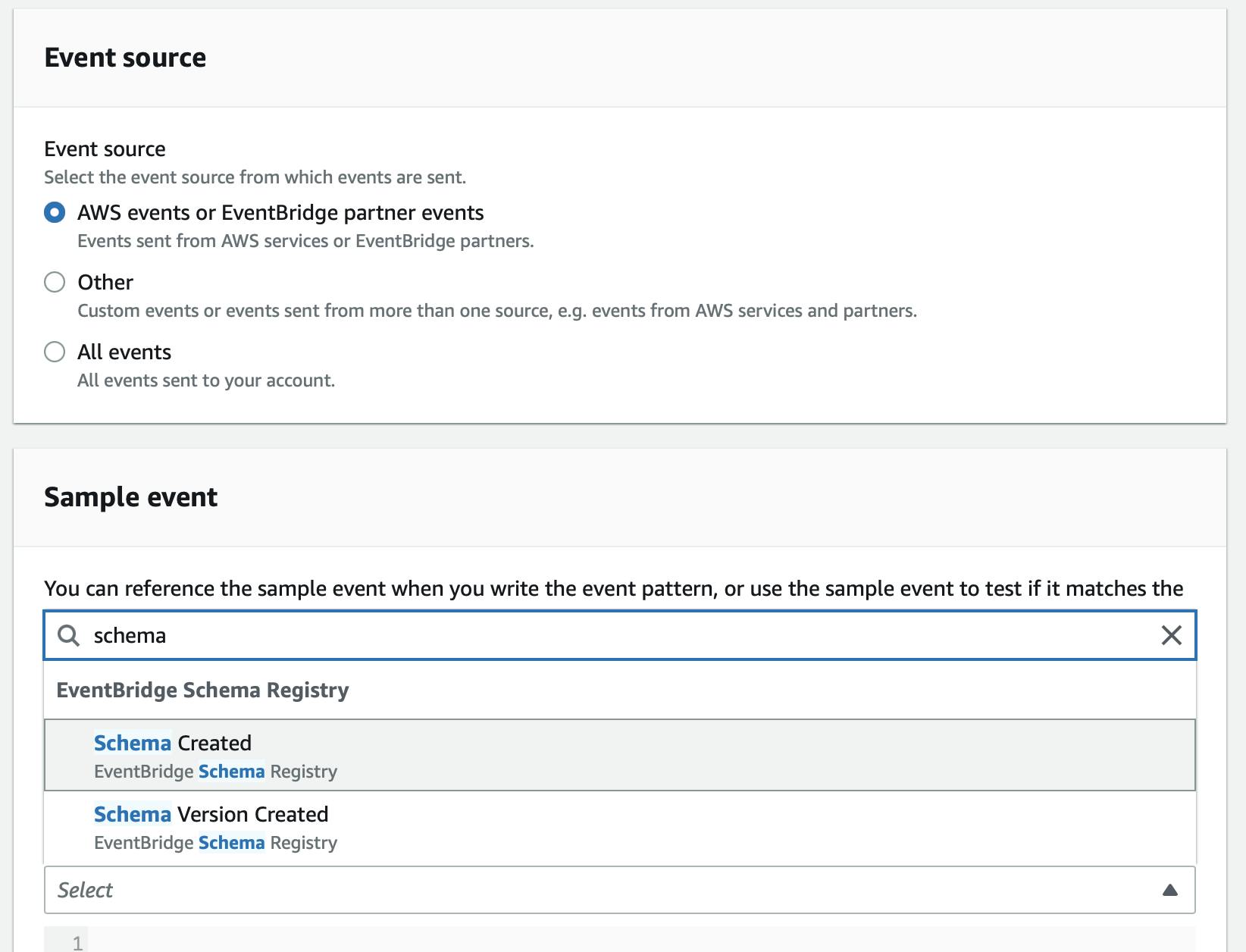
From here you could:
- You could extend the schemas by Improving EventBridge Schema Discovery
- Maybe you want to store additional information from GitHub webhooks into DynamoDB
- Track EventBridge Rule changes via CloudFormation deployments
What would you do next?
🙌 If anything wasn't clear or if you want to be notified on future posts... feel free to hit me up on Twitter @martzcodes.