




In my previous post experimenting with EventBridge, Evaluating AWS EventBridge Schema Discovery I used AWS Schema Registry with Event Discovery and tried out a 3rd party project called EventBridge Atlas to generate documentation.
It was fairly successful but required a lot of manual action to keep the docs up to date... and you and I both know that wouldn't happen in practice. EventBridge Atlas was neat, but ultimately it just pulled the schema registry as-is and then parsed it into multiple formats (when only one is really necessary).
So in this part I'll cut out the middleman and just parse straight into AsyncAPI format, which was my preferred format from the ones EB Atlas parsed into.
Architecture and Setup
In part 1 I learned that the default EventBus for an account receives events anytime a Schema is created or updated to the EventBridge Schema Registry. From there we can trigger a lambda function and process the schema.
Building onto my previous code, I'll create the target function, add a policy to it that allows it to read the schemas and grant it access to DynamoDB. Then I'll create the rule to subscribe to aws.schemas events which are the create/update events for the schema registry.
const targetFunction = new NodejsFunction(this, 'targetFunction', {
functionName: `${this.stackName}targetFunction`,
...lambdaProps,
entry: `${__dirname}/target.ts`,
memorySize: 1024,
timeout: Duration.seconds(60),
environment: {
API_BUCKET: inquisitorApiBucket.bucketName,
INQUISITOR_BUS: bus.eventBusArn,
},
});
const schemaPolicy = new PolicyStatement({
effect: Effect.ALLOW,
actions: [
'schemas:*',
],
resources: [
`arn:aws:schemas:${this.region}:${this.account}:registry/*`,
`arn:aws:schemas:${this.region}:${this.account}:schema/*`,
],
});
targetFunction.addToRolePolicy(schemaPolicy);
table.grantReadWriteData(targetFunction);
inquisitorApiBucket.grantReadWrite(targetFunction);
const rule = new Rule(this, 'schemaRule', {
description: 'This is a rule for schema events...',
eventPattern: {
source: ['aws.schemas'],
},
});
rule.addTarget(new LambdaFunction(targetFunction));
One thing Schema Registry doesn't do is infer optional parameters. If the first time it processes an event there's a property called "something" and the next time "something" isn't there... the 2nd version of the schema will be as if "something" never existed. That wouldn't be optimal if you're trying to export TypeScript types / interfaces for the schema. You could also argue the Best Practice is to NOT have optional parameters in your events and to just emit variations of the detail-types... and you'd probably be right.

To fix that we'll store the schemas (and the AsyncAPI Spec) in DynamoDB and improve them over time. That's what the target.ts lambda function does. It receives the aws.schemas event, downloads the OpenAPI v3 flavor of the schema that was updated, and then merges it into the AsyncAPI Spec that's already stored in DynamoDB.
Great, so our work is done now, right?
Not quite. I want to host the actual documentation portion. I decided to both store the AsyncAPI Spec in DynamoDB and also to save it as a yaml file to a public s3 bucket*... but I'd still like to have a UI to look at it with.
AsyncAPI has a react project which is essentially what their "playground" uses. Use the Next branch... trust me.
It doesn't have to be rebuilt ever really... the way I have it set up is it just makes an http request to s3 and downloads the yaml file from there. This is actually a little overkill... it'd be easy enough to spin up a RestAPI and get the same spec via API request instead of s3... but it doesn't hurt for demo purposes so I decided to keep it.
To add a frontend to an existing projen project you can extend the .projenrc.js file. All you have to do is add a subproject via projen and it will install everything necessary in a subdirectory in the project. Pretty neat.
const frontendProject = new web.ReactTypeScriptProject({
defaultReleaseBranch: 'main',
outdir: 'frontend',
parent: project,
name: 'cdk-s3-website',
deps: ['@asyncapi/react-component@v1.0.0-next.14', 'axios'],
jest: false,
});
frontendProject.setScript('test', 'npx projen test -- --passWithNoTests');
frontendProject.synth();
I also had to update the build script for the parent project project.setScript('build', 'cd frontend && npm run build && cd .. && npx projen build');.
This creates the react app, but doesn't actually deploy it anywhere. Fortunately that is as simple as adding a bucket and BucketDeployment:
const siteBucket = new Bucket(this, 'SiteBucket', {
websiteIndexDocument: 'index.html',
websiteErrorDocument: 'error.html',
publicReadAccess: true,
cors: [
{
allowedMethods: [HttpMethods.GET, HttpMethods.HEAD],
allowedOrigins: ['*'],
allowedHeaders: ['*'],
exposedHeaders: ['ETag', 'x-amz-meta-custom-header', 'Authorization', 'Content-Type', 'Accept'],
},
],
removalPolicy: RemovalPolicy.DESTROY,
autoDeleteObjects: true,
});
// Deploy site contents to S3 bucket
new BucketDeployment(this, 'BucketDeployment', {
sources: [Source.asset('./frontend/build')],
destinationBucket: siteBucket,
});
So now, when I run npx projen deploy it deploys all the automation needed to self-generate EventBridge Schema documentation. It looks like this:
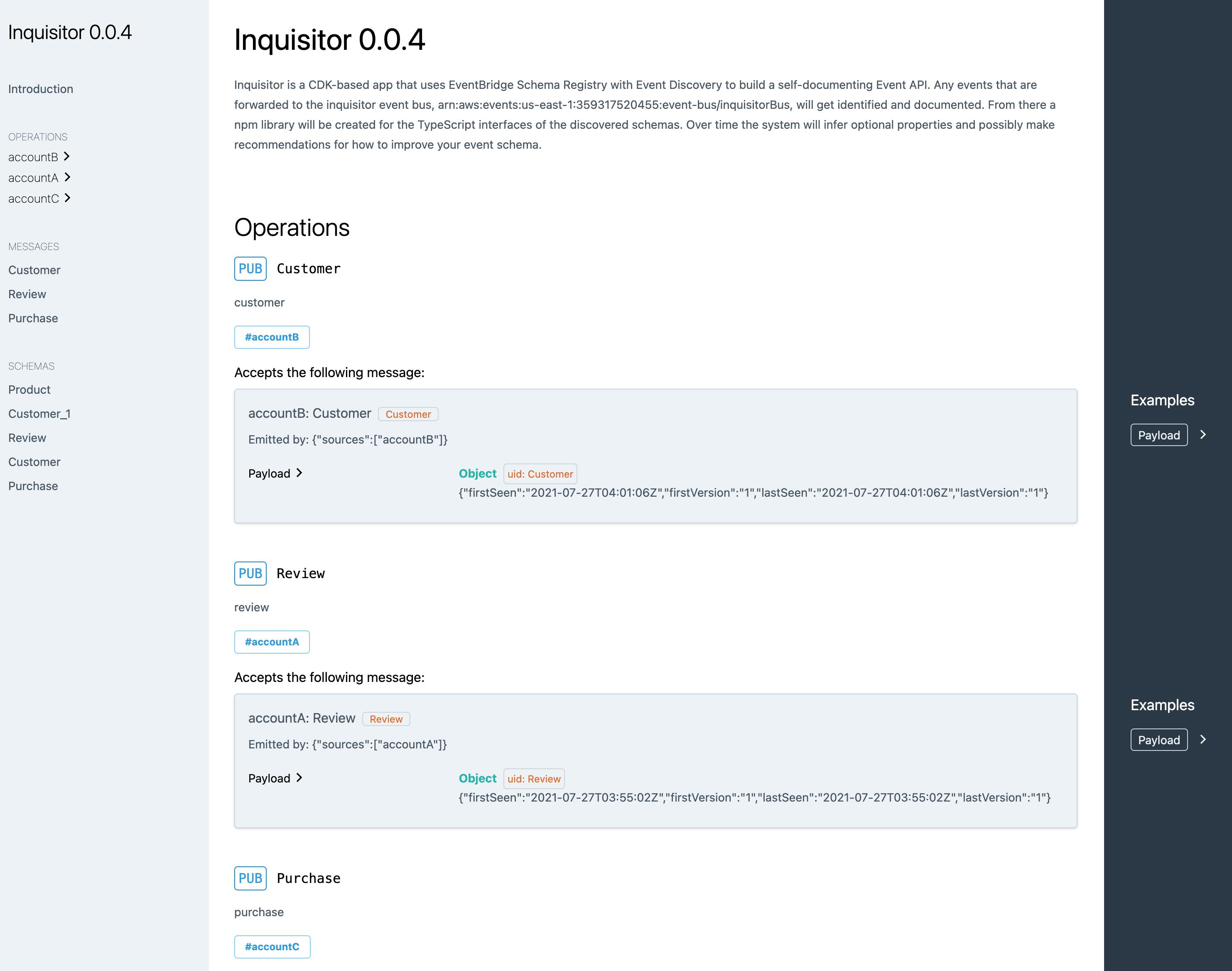
You can see this in action here.
There is still an inherent ~5 minute delay for the Schema Registry to process the events and this is observable from both the AWS Console and the aws.schemas events.
One more thing worth mentioning... Schema Registry won't create a new Schema Version for an event with the same properties that comes from a different detail-type... which I suppose is nice? but it doesn't help with the observability / traceability I was hoping to get out of this.
What's Next?
As I started this "series" I thought this was only going to be a two-parter... but as I delved deeper into what this could do I was quickly overwhelmed with possibilities.

Part 3 will still be generating an npm package with the TypeScript interfaces inferred from the AsyncAPI. The schemas are stored in JSONSchema format and there are several code generators that can go from JSONSchema / OpenAPI Schema -> TypeScript. It will probably use an event to trigger a CodeBuild pipeline.
The AsyncAPI React App is very extensible. Which is good because there are definitely gaps in my current approach. There's definitely a need for the occasional manual override in the schemas. In my code I used the schema description properties to store stringified JSON with things like "first seen" / "last seen"... but it could also be used for overrides.
Right now any time an event gets processed by Schema Registry whatever fields are present are marked as "required" and if old properties aren't there they just cease to exist. My lambda counters that by merging the old with the new... but I can definitely see cases where I'd need to go in and say... "this property was a mistake... get rid of it" or "this should always be required". Also if there are any errant events that pass through the bus (dev events / misplaced rules / whatever) and I need to remove an entire message type... that would be nice to adjust.
In these cases, npm version-wise, I think removing messages would be a major version change... while removing / updating properties would be minor version changes. The existing already code bumps the patch version with every update (which should be backwards compatible).
So Part 4 (and/or 5) could be adding the Rest/Http API and the corresponding React App changes to edit those things.