



Photo by Federico Burgalassi on Unsplash
Automate Documenting API Gateways in EventCatalog
Part 2 in a Series on Event Driven Documentation


In this series we're going to SUPERCHARGE developer experience by implementing Event Driven Documentation. In part 1 we used CDK to deploy EventCatalog to a custom domain using CloudFront and S3. In this post we'll use AWS Service Events from CloudFormation to detect when an API Gateway has deployed and export the OpenAPI spec from AWS to bundle it in our EventCatalog. In Part 3 we'll export the JSONSchema of EventBridge Events using schema discovery and bundle them into the EventCatalog.
🛑 Not sure where to start with CDK? See my CDK Crash Course on freeCodeCamp
The architecture we'll be deploying with CDK is:

We'll focus on creating an "Account Stack" that will subscribe to CloudFormation Events within that stack and forward them to a central stack (possibly in another account) to be included in the EventCatalog.
💻 The code for this series is published here: https://github.com/martzcodes/blog-event-driven-documentation
🤔 If you have any architecture or post questions/feedback... feel free to hit me up on Twitter @martzcodes.
Wait... Account Stack?
This architecture is designed to be modular. If you only have a single AWS account you could install all of the constructs from this series in a single stack and still get the same result.
At my work we practice Domain Driven Design. Because of this we end up having over 30 AWS Accounts in use by 10+ teams. There are plenty of cases where these domains need to interact with each other via API gateway and EventBridge events, so we wanted a single place to hold the documentation for all of them.
We do this by having a central "Watcher" stack and deploy an "Account" stack to each AWS Account. CDK can handle these with a single cdk deploy command (provided you have the right permissions / have bootstrapped the trusts). In practice, I deploy these Account Stacks in 3 waves (one for each environment type: dev -> qa -> prod).
The Account Stack is responsible for monitoring the API gateway deployments (and in Part 3... the EventBridge schemas) within its domain. When something we care about changes in an account, the Account Stack forwards it to the central AWS Account with the "Watcher" stack where it gets processed.
Creating the Account Stack
Our "Account" stack will only need two main things: A bucket to store our account artifacts and a lambda to process AWS Service events and fetch the API gateway spec. The components of this stack will live in the ./lib/account project folder.
Spec Bucket and Event Bus
💡Looking ahead... we can re-use the spec bucket for both API Gateway specs and EventBridge schemas. We'll create this on the stack itself so we can share it with the CloudFormation listener construct as well as the construct we make in part 3.
const specBucket = new Bucket(this, `AccountSpecBucket`, {
removalPolicy: RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED,
lifecycleRules: [ { expiration: Duration.days(7), }, ],
autoDeleteObjects: true,
});
The bucket follows my "standard" Bucket template with the addition of setting lifecycle rules on the objects. This will expire the objects after 7 days. This is probably unnecessary since the bucket will never grow too large in size, but it doesn't hurt to have.
We also need access to the default Event Bus that we'll be using to grant permissions to our lambda to put events with. We can import that within the stack too:
const bus = EventBus.fromEventBusName(this, `bus`, "default");
CloudFormation Listener Construct
Next, we'll create a construct. When I make constructs I like to start out with a simple template where I define the construct along with some props:
export interface CloudFormationListenerProps {
bus: IEventBus;
specBucket: Bucket;
}
export class CFListener extends Construct {
constructor(
scope: Construct,
id: string,
props: CloudFormationListenerProps
) {
super(scope, id);
const { bus, specBucket } = props;
}
}
Our construct only needs to 1) create the lambda and 2) create a rule to trigger the lambda.
Our lambda will be using AWS Service events by subscribing to CloudFormation service events. Any time a CloudFormation (CDK) stack deploys with changes to an API Gateway we'll want to export that gateway's OpenAPI Spec.
😢 Unfortunately there aren't any service events for API Gateway deployments, which is why we're using CloudFormation Events.
const cfFn = new NodejsFunction(this, `cfStatusFn`, {
runtime: Runtime.NODEJS_16_X,
entry: join(__dirname, `./cf-listener-lambda.ts`),
logRetention: RetentionDays.ONE_DAY,
initialPolicy: [
new PolicyStatement({
effect: Effect.ALLOW,
actions: ['cloudformation:Describe*', 'cloudformation:Get*', 'cloudformation:List*', 'apigateway:Get*'],
resources: ['*']
}),
],
});
Here we grant the lambda access to some CloudFormation actions that will be used to fetch information on the stack, and we also include apigateway:Get* since we'll use that to get the OpenAPI Spec export.
Our lambda needs to be able to read and write from our spec bucket, and to putEvents onto the event bus:
specBucket.grantReadWrite(cfFn);
cfFn.addEnvironment('SPEC_BUCKET', specBucket.bucketName);
bus.grantPutEventsTo(cfFn);
Finally we create the rule to invoke the lambda:
new Rule(this, `cfRule`, {
eventBus: props.bus,
eventPattern: {
source: ["aws.cloudformation"],
detailType: ["CloudFormation Stack Status Change"],
detail: {
"status-details": {
status: ["CREATE_COMPLETE", "UPDATE_COMPLETE", "IMPORT_COMPLETE",],
},
},
},
targets: [new LambdaFunction(cfFn)]
});
⚠️ We only care about events where the stack was successfully updated. We don't want to re-export the OpenAPI spec for a failed deployment.
CloudFormation Listener Lambda
Our lambda is actually slightly complicated. Each CloudFormation SDK API has slightly different things within it (and the property names even change). For example... there's no way to get API Gateway Ids out of it. We're going to end up having to:
- Describe the Stack
- Get (and paginate through) the CloudFormation ChangeSet
- Get the "processed" Stack Template
- List all of the API Gateways and Find the API Gateways that match our Stack Id
- Export the OpenAPI specs from the API Gateway to S3
- Emit an Event that OpenAPI Specs were exported
We'll be using the AWS-SDK v3 clients to do all of this.
Describe the Stack
We want the "friendly" stack name as part of our output. We get this by describing the stack:
const StackName = event.detail["stack-id"];
const describeCommand = new DescribeStacksCommand({ StackName });
const stacks = await cf.send(describeCommand);
const stack = stacks.Stacks?.[0];
Get the ChangeSets
Next, we only care about these events if the ChangeSet includes API Gateways that change. We'll paginate through the ChangeSet sdk and if we see an API Gateway we'll stop:
const ChangeSetName = stack?.ChangeSetId;
const getChangeSets = async (NextToken?: string): Promise<boolean> => {
const changeSet = await cf.send(
new DescribeChangeSetCommand({
StackName,
ChangeSetName,
NextToken,
})
);
const apiChanged =
(changeSet.Changes || []).filter((change) =>
change.ResourceChange?.ResourceType?.startsWith("AWS::ApiGateway")
).length !== 0;
if (apiChanged) {
return true;
}
if (changeSet.NextToken) {
return getChangeSets(changeSet.NextToken);
}
return false;
};
const apiChanged = await getChangeSets();
We use change.ResourceChange?.ResourceType?.startsWith("AWS::ApiGateway") to detect if API Gateways had any changes.
Get the Template
Next we get the "processed" CloudFormation template. "Processed" means it has the ARNs in it after everything is deployed / resolved. We need this so we can get the names of the API Gateway stages (which is unfortunately not in any other query).
const getTemplateCommand = new GetTemplateCommand({
StackName,
TemplateStage: TemplateStage.Processed,
});
const template = await cf.send(getTemplateCommand);
if (!template.TemplateBody) {
return;
}
const resources: Record<string, any> = JSON.parse(
template.TemplateBody
)?.Resources;
const apiStages = Object.values(resources).filter(
(res: any) => res.Type === "AWS::ApiGateway::Stage"
);
Find our API Gateways
🤢 This part sucks. There's no way to query API Gateways for a particular stack... so you have to list them all and filter by the apigateway being tagged with a cloudformation stack id:
const getApis = new GetRestApisCommand({
limit: 500,
});
const apiRes = await api.send(getApis);
if (!apiRes.items) {
return;
}
const apis = apiRes.items.reduce((p, c) => {
if (c.tags?.["aws:cloudformation:stack-id"] !== StackName) {
return p;
}
if (c.tags?.["aws:cloudformation:logical-id"]) {
return { ...p, [c.tags?.["aws:cloudformation:logical-id"]]: c.id! };
}
return p;
}, {} as Record<string, string>);
Export the OpenAPI Specs to S3
Now that we know what APIs are in our stack, we can export the OpenAPI Specs:
for (let j = 0; j < apiStages.length; j++) {
const restApiId = apis[apiStages[j].Properties.RestApiId.Ref];
const stageName = apiStages[j].Properties.StageName;
const exportCommand = new GetExportCommand({
accepts: "application/json",
exportType: "oas30",
restApiId,
stageName,
});
const exportRes = await api.send(exportCommand);
const oas = Buffer.from(exportRes.body!.buffer).toString();
apiSpecs[`${restApiId}-${stageName}`] = JSON.parse(oas);
}
And upload them to our Account's Spec Bucket:
const fileLoc = {
Bucket: process.env.SPEC_BUCKET,
Key: `openapi/${stack.StackName}/specs.json`,
};
const putObjectCommand = new PutObjectCommand({
...fileLoc,
Body: JSON.stringify(apiSpecs),
});
await s3.send(putObjectCommand);
Emit the Event
Finally, we can emit the Event to the default Event Bus. We get a pre-signed URL and send that to EventBridge with the "friendly" stack name and the the number of API Specs contained within:
const getObjectCommand = new GetObjectCommand({
...fileLoc,
});
const url = await getSignedUrl(s3, getObjectCommand, { expiresIn: 60 * 60 });
const eventDetail: OpenApiEvent = {
stackName: stack.StackName!,
apiSpecs: Object.keys(apiSpecs).length,
url,
};
const putEvent = new PutEventsCommand({
Entries: [
{
Source,
DetailType: BlogDetailTypes.OPEN_API,
Detail: JSON.stringify(eventDetail),
},
],
});
await eb.send(putEvent);
We use pre-signed URLs because they're easy and flexible. We could also grant read access to the Watcher Stack's Account Principal. The spec files are generally too large to include in the event body.
Forward Events
⚠️ For single-account setups, this step isn't necessary. But for cross-account setups you'd need to forward your events from your account's bus to the target bus:
if (watcherAccount && watcherAccount !== Stack.of(this).account) {
new Rule(this, `WatcherFwd`, {
eventPattern: {
source: [Source],
},
targets: [new EventBusTarget(
EventBus.fromEventBusArn(this, `watcher-bus`, `arn:aws:events:${Stack.of(this).region}:${watcherAccount}:event-bus/default`)
)]
});
}
This rule forwards anything with our "shared" Source to the "Watcher" account's default bus.
Updating the Watcher Stack
Now we have events "flowing" to our "Watcher" account and we need to use them. The next part of our architecture will subscribe to these events, copy the specs to our Watcher Bucket and bootstrap the needed markdown files for EventCatalog to use them.
Watcher Spec Construct
The Watcher spec construct will grant cross-account permissions (if in a multi-account situation) and create a new bucket for the specs.
this.bus = EventBus.fromEventBusName(this, `bus`, "default");
const { watchedAccounts = [] } = props;
watchedAccounts.forEach((watchedAccount) => {
if (watchedAccount !== Stack.of(this).account) {
this.bus.grantPutEventsTo(new AccountPrincipal(watchedAccount));
}
});
In a cross-account situation, buses need to grant access by ARN to allow other buses to have putEvent access (which is used by the rules). We didn't do this in the "Account" stack because the Watcher stack doesn't emit events.
And then we create the bucket.
this.specBucket = new Bucket(this, `WatcherSpecBucket`, {
removalPolicy: RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED,
autoDeleteObjects: true,
});
new CfnOutput(this, `WatcherSpecBucketOutput`, {
value: this.specBucket.bucketName,
});
Here the CfnOutput is useful because later we'll need the bucket's name for our post-processing script.
Add Rule Method
Next we need to create a lambda and invoke it via a rule. We know we're going to use a similar pattern in part 3... so we can abstract this a little bit. Both will need a lambda invoked by a rule... so we'll create an addRule method on our Construct:
const fn = new NodejsFunction(this, lambdaName, {
runtime: Runtime.NODEJS_16_X,
entry: join(__dirname, `./${lambdaName}.ts`),
logRetention: RetentionDays.ONE_DAY,
});
this.specBucket.grantWrite(fn);
fn.addEnvironment("SPEC_BUCKET", this.specBucket.bucketName);
new Rule(this, `${lambdaName}Rule`, {
eventBus: this.bus,
eventPattern: {
source: [Source],
detailType: [detailType],
},
targets: [new LambdaFunction(fn)],
});
Copy the Spec(s)
To reduce the number of file transfers our Account Stack combined (potentially) multiple OpenAPI specs in a single file. We'll grab that file and split it up.
const res = await fetch(event.detail.url);
const specs = (await res.json()) as Record<string, any>;
const gateways = Object.keys(specs);
for (let j = 0; j < gateways.length; j++) {
const fileLoc = {
Bucket: process.env.SPEC_BUCKET,
Key: `openapi/${event.account}/${event.detail.stackName}/${gateways[j]}/openapi.json`,
};
const putObjectCommand = new PutObjectCommand({
...fileLoc,
Body: JSON.stringify(specs[gateways[j]], null, 2),
});
await s3.send(putObjectCommand);
}
We use the pre-signed url to fetch the file and then we store each spec within it as its own file. We're storing this with a templated path that we'll be able to extract information out of later.
Bootstrap the Spec(s) with Markdown into EventCatalog
Unfortunately with EventCatalog you can't just throw it a bunch of spec files and have everything work. It's a static site and those spec files need some markdown in a particular folder structure in order to work. It does have a handy domain concept though and we're going to leverage that to split out things by AWS Account.
documentation
├── domains
│ ├──AWS Account A
│ │ ├──index.md
│ │ ├──services
│ │ │ └──API Gateway
│ │ │ └──index.md
│ │ │ └──schema.json
│ ├──AWS Account B
│ │ ├──index.md
│ │ ├──services
│ │ │ └──API Gateway
│ │ │ └──index.md
│ │ │ └──schema.json
│ │ ├──events
├── eventcatalog.config.js
├── package.json
├── README.md
└── yarn.lock
So we need to run a script that pulls the S3 files and processes them into this structure, creating the files as-needed. We'll need to run this with an AWS Profile that has access to read from the bucket.
Locally, we're going to store this in ./lib/prepare a subfolder and we'll add a script to our package.json to run it: "prepare:catalog": "ts-node ./lib/prepare $SPEC_BUCKET",
We also use the WatcherSpecBucketOutput from the CfnOutput we made when creating the bucket and export SPEC_BUCKET=<WatcherSpecBucketOutput>.
List the files
We'll use the v3 aws-sdk client to list the objects with the openapi/ prefix.
const listBucketObjectsCommand = new ListObjectsCommand({
Bucket,
Prefix: "openapi/",
});
const bucketObjects = await s3Client.send(listBucketObjectsCommand);
const specs = bucketObjects.Contents!.map((content) => {
const key = content.Key!;
const splitKey = key.split("/");
const account = splitKey[1];
const stack = splitKey[2];
const apiId = splitKey[3].split(".")[0];
return { key, account, stack, apiId };
});
From there we'll map those objects splitting out the useful information from the key name.
Create the Domain folder
Next, we need to make sure the "Domain" folder exists and if not, create it with the markdown files.
const domain = `acct-${account}`;
const domainPath = join(__dirname, `../../catalog/domains/${domain}/`);
mkdirSync(domainPath, { recursive: true });
if (!existsSync(join(domainPath, `./index.md`))) {
const domainMd = [
`---`,
`name: ${domain}`,
`summary: |`,
` This is the automatically stubbed documentation. Please replace this by clicking the edit button above.`,
`owners:`,
` - martzcodes`,
`---`,
];
writeFileSync(join(domainPath, `./index.md`), domainMd.join("\n"));
}
It's a very simple stub that just says it was automatically stubbed.
⚡️You can add yourself as a contributor to the ./catalog/eventcatalog.config.js file and then list yourself as an owner in the markdown, and you'll be displayed on the page.
Create the Service Folder
Next, we need to create the service folder.
const basePath = join(domainPath, `./services/${apiName}`);
mkdirSync(basePath, { recursive: true });
writeFileSync(join(basePath, `./openapi.json`), spec);
if (!existsSync(join(basePath, `./index.md`))) {
const apiMd = [
`---`,
`name: ${apiName}`,
`summary: |`,
` This is the automatically stubbed documentation for the ${apiName} API (${specMeta.apiId}) in the ${specMeta.stack} stack. Please replace this.`,
`owners:`,
` - martzcodes`,
`---`,
``,
`<OpenAPI />`,
];
writeFileSync(join(basePath, `./index.md`), apiMd.join("\n"));
}
Of note here is that we're NOT re-stubbing the file if the file already exists. The idea here is that developers would come into the catalog project and update their documentation via commit. Spec/Schema discovery will be automated and from that point it's easily extended by the devs. 💪
Update the BucketDeployment
Last (but not least)... we want to update our BucketDeployment from Part 1 to run the prepare:catalog script as part of the cdk deployment. This means that any time the watcher stack is deployed, it'll pull the files from S3 and bootstrap any that weren't already defined! The asset generation then becomes:
const bundle = Source.asset(uiPath, {
assetHash: `${Date.now()}`,
bundling: {
command: ["sh", "-c", 'echo "Not Used"'],
image: DockerImage.fromRegistry("alpine"), // required but not used
local: {
tryBundle(outputDir: string) {
execSync("npm run prepare:catalog"); // <-- added this
execSync("cd catalog && npm i");
execSync("cd catalog && npm run build");
copySync(uiPath, outputDir, {
...execOptions,
recursive: true,
});
return true;
},
},
},
});
See It In Action
🙈 SPOILER ALERT: You can see this in action at docs.martz.dev which will be the result of this series🤫
I went ahead and deployed my blog post Create a Cross-Account IAM Authorized APIGateway with CDK in order to get some files to work with and then I CDK deployed this project.
The domain was created:
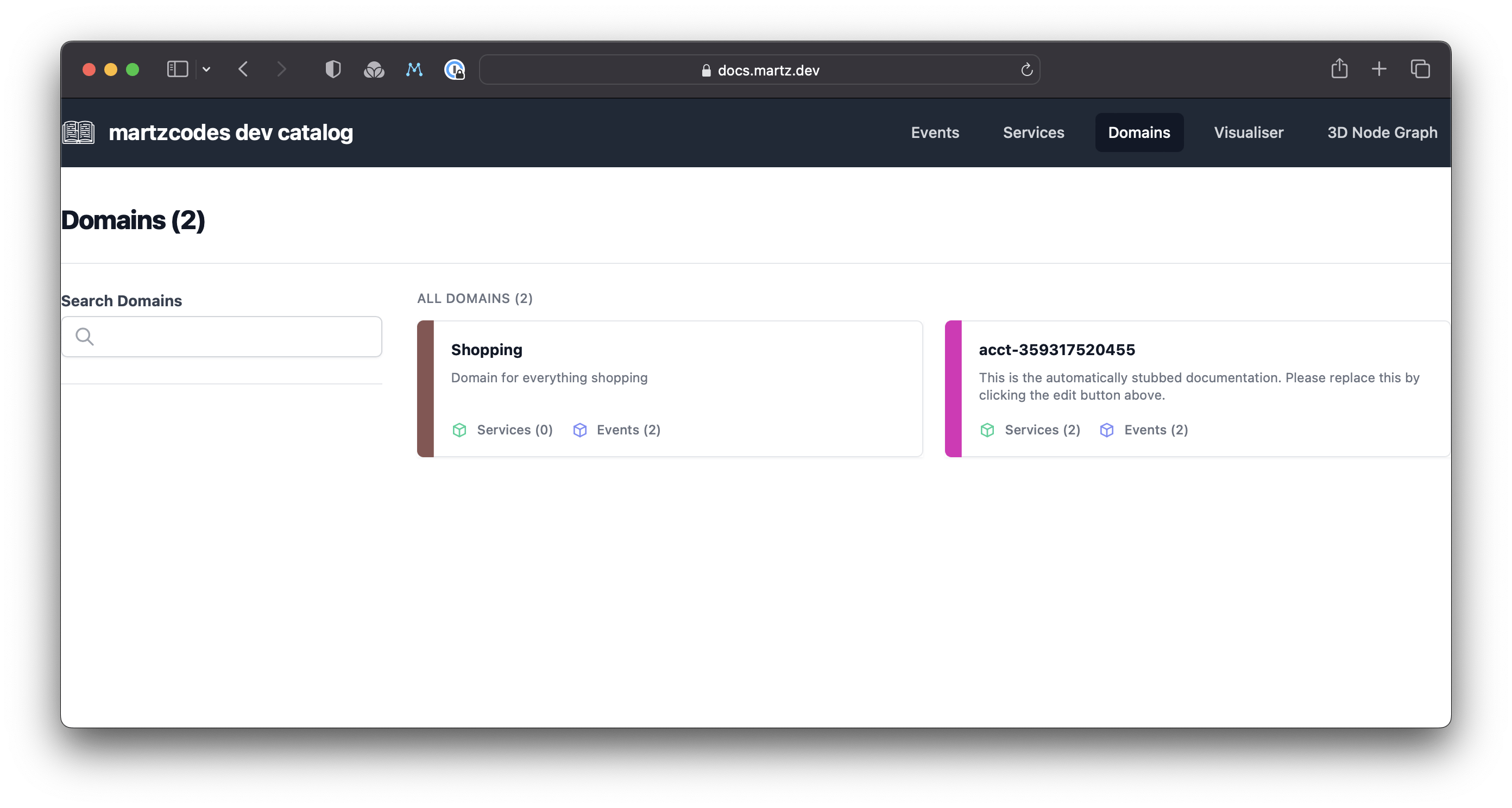
And the Service was created with the exported OpenAPI spec!
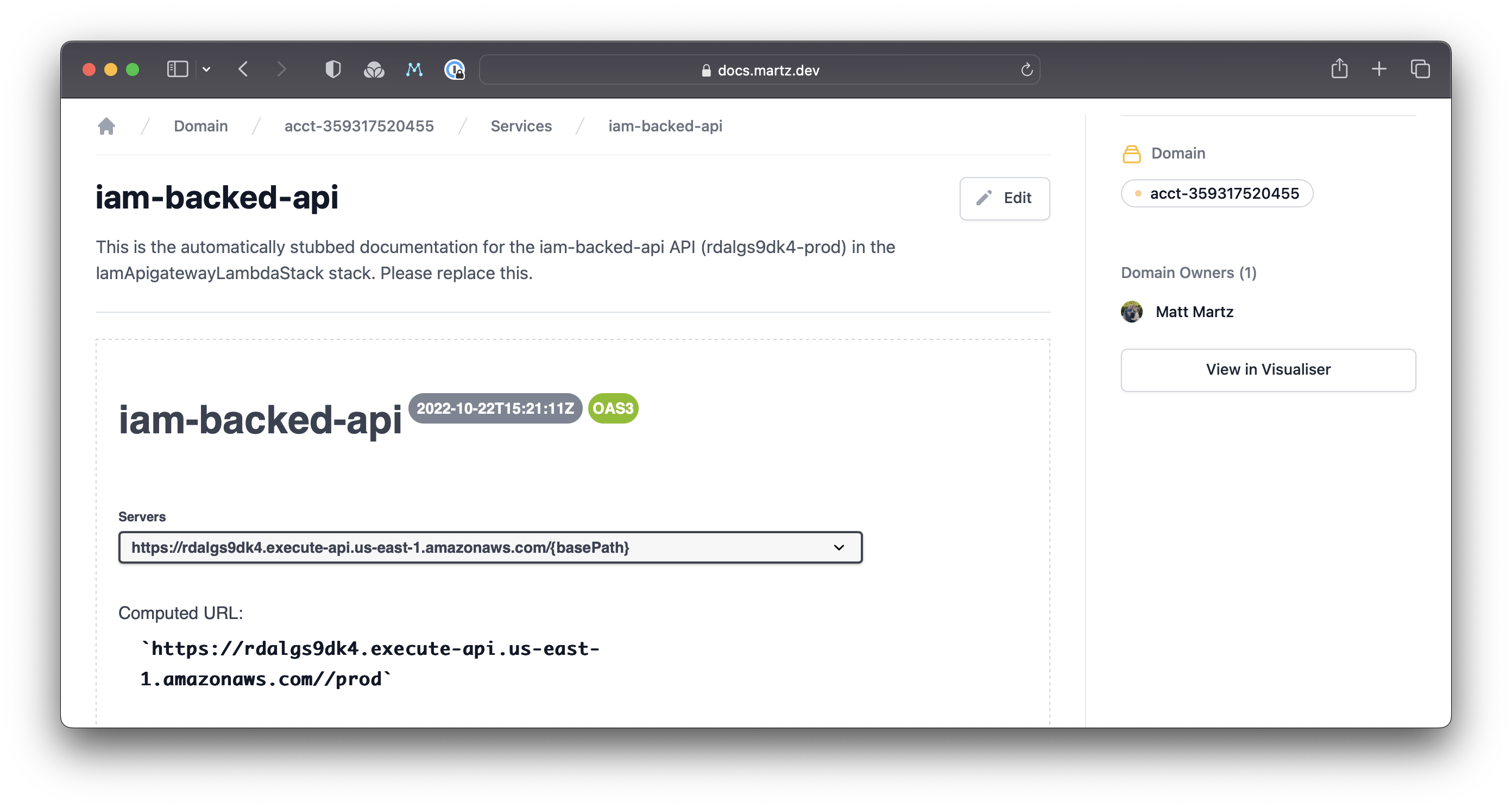
What's Next?
Now that we have automatic API Gateway specs we're only missing the EventBridge Event Schemas... and that's what we'll be doing in Part 3.
🙌 If anything wasn't clear or if you want to be notified on when I post part 3... feel free to hit me up on Twitter @martzcodes.