


Supercharging a Serverless Slackbot with Amazon Bedrock
Event-Driven Architecture for AI-Powered DevOps


In the dynamic world of software development, staying abreast of changes and deployments is crucial for team collaboration and efficiency. In my previous post, From Code to Conversation: Bridging GitHub Actions and Slack with CDK, I introduced a solution that used AWS Cloud Development Kit (CDK) to deploy a Lambda and DynamoDB-powered Slack App that gave teams push-button deployments between environments from Slack. Building on that foundation, this follow-up article delves into a significant enhancement — the integration of Amazon Bedrock, AWS's generative AI service, to revolutionize how we handle commit logs and release summaries.
The updated Deployer Bot is not just smarter; it's designed to be more responsive and informative by utilizing an event-driven architecture that streamlines notifications and summaries. By tapping into the power of generative AI, the bot now offers concise, human-readable summaries of commits and release notes, making it easier for teams to grasp the impact of their work at a glance.
As an example... When I added this to my team's internal Slack Bot (based on the previous post's work). Bedrock provided this commit summary: "The commit enables the bot to summarize code changes and releases using AI via AWS Bedrock, including analyzing commits for risks and generating release prep recommendations between environments.". My commit message was only "bedrock... not handling brext w/ios though". 🤯
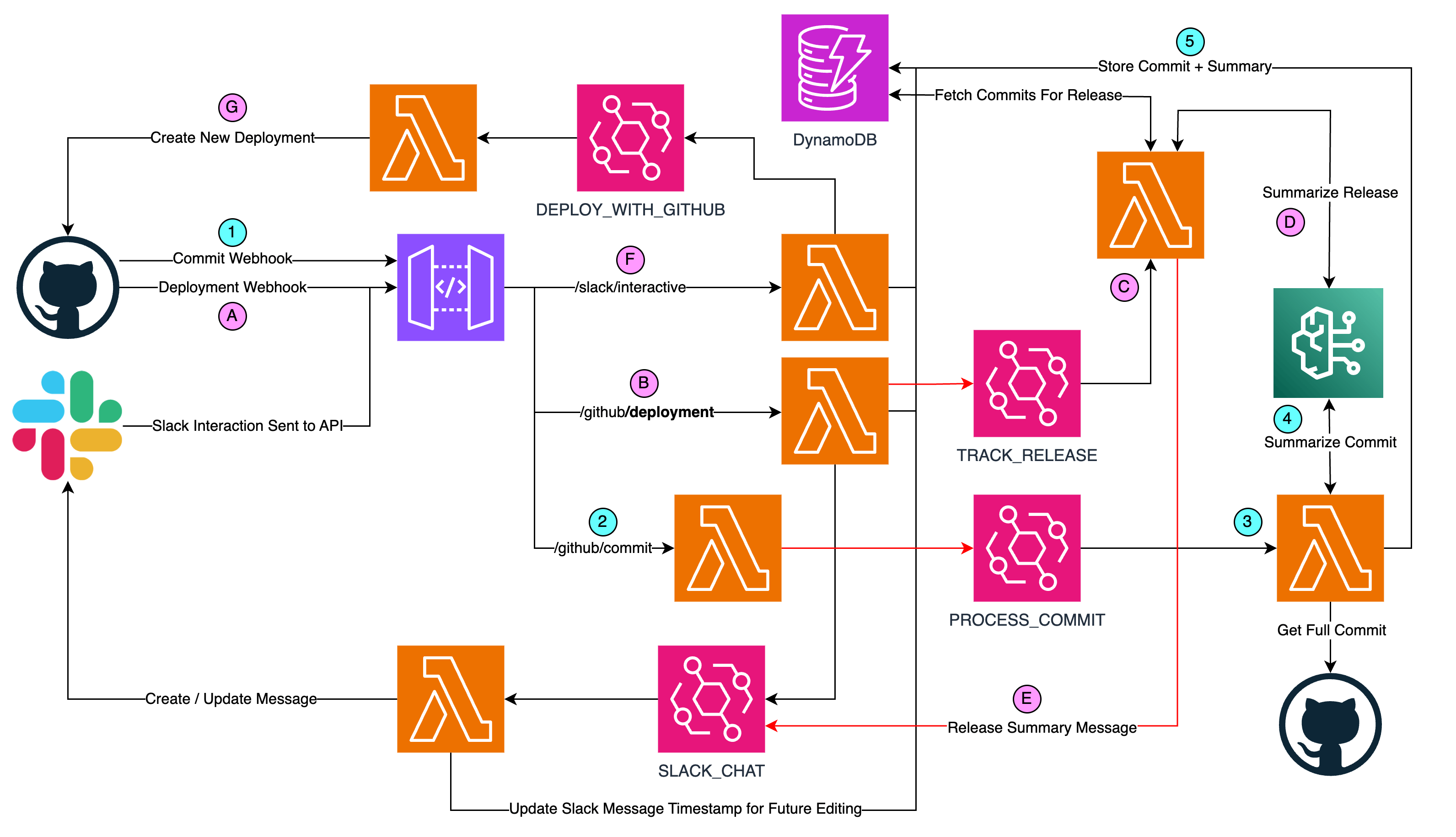
Commits trigger webhooks that flow through a series of AWS Lambda functions, orchestrating the process from commit tracking to AI-powered summarization, culminating in neatly packaged per-environment releases communicated via Slack. As part of the commit analysis and summarization, we get results like this on a completed deployment:
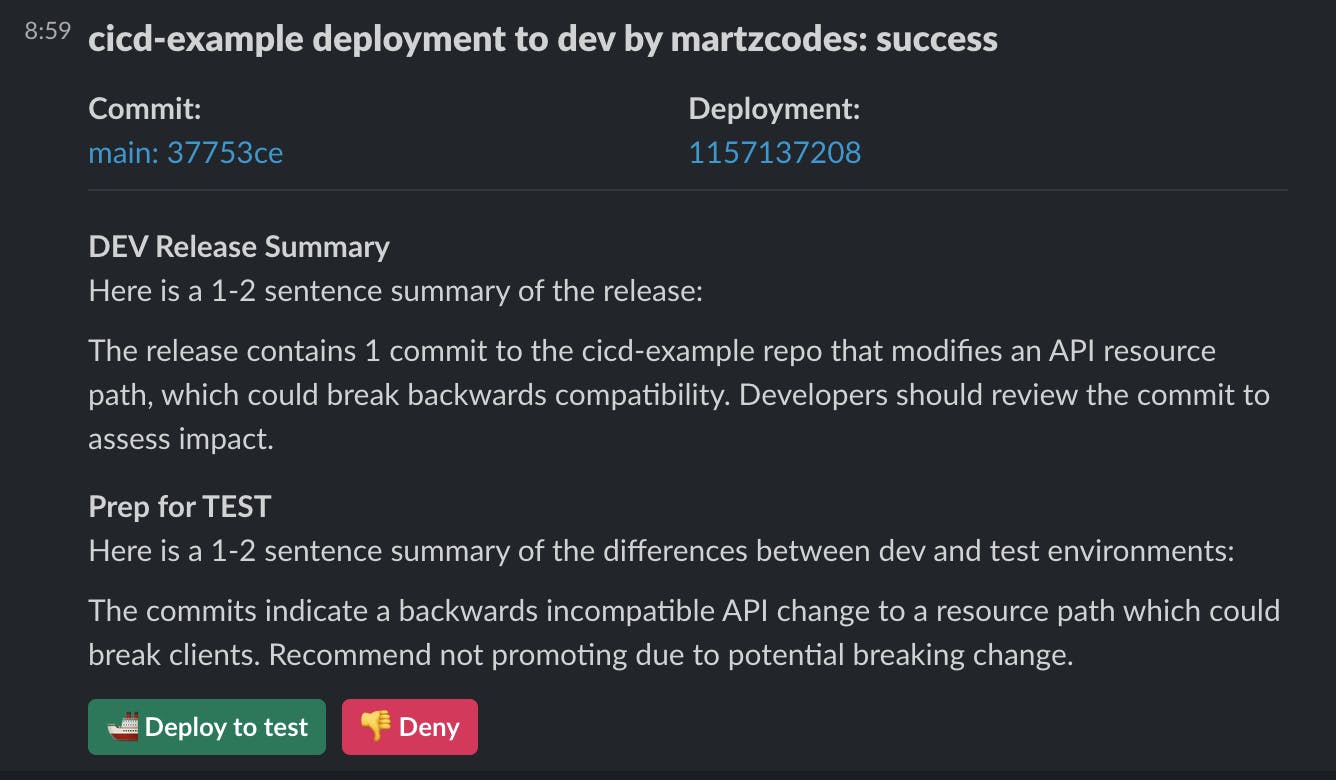
In this article, we'll explore the rationale behind each architectural decision, the process of incorporating Amazon Bedrock into our bot, and the benefits that an event-driven model brings to our CI/CD pipelines. For the DevOps enthusiasts and the code-curious alike, the complete codebase is accessible on GitHub at https://github.com/martzcodes/blog-cicd-bedrock-releases.
A quick note on costs: Amazon Bedrock and the models they run are NOT free. In my case, I've restricted the analysis to a limit of 10000 "tokens" so the max cost of processing a large commit or release for my case is about $0.10 - $0.20. Claude's upper token limit is 100k tokens which would have a max cost of $1-2 per model invocation.
Revamping the Architecture: Embracing Event-Driven Design
The transformation of the Deployer Bot’s architecture to an event-driven model marks a significant enhancement from its original design. This section will explore the rationale behind adopting an event-driven approach, the benefits it offers, and how it is implemented within the context of the Deployer Bot integrated with Amazon Bedrock for AI-powered commit summarization and release management.
Understanding Event-Driven Architecture (EDA)
Event-Driven Architecture (EDA) is a design paradigm centered around the production, detection, consumption, and reaction to events. An event is any significant state change that is of interest to a system or component. EDA allows for highly reactive systems that are more flexible, scalable, and capable of handling complex workflows. It is particularly well-suited for asynchronous data flow and microservices patterns, often found in cloud-native environments.
Why Event-Driven?
The original Deployer Bot followed a more traditional request/response model, where actions were triggered by direct requests. While functional, this approach had limitations in terms of scalability and real-time responsiveness. The integration of Amazon Bedrock and the necessity to process and summarize commit data presented an opportunity to redesign the architecture to be more reactive and efficient.
Benefits of Event-Driven Architecture
Scalability: EDA allows each component to operate independently, scaling up or down as needed without impacting the entire system.
Resilience: The decoupled nature of services in EDA results in a system that is less prone to failures. If one service goes down, the rest can continue to operate.
Real-Time Processing: Events can be processed as soon as they occur, providing immediate feedback and actions, which is crucial for CI/CD workflows.
Flexibility: New event consumers can be added to the architecture without impacting existing workflows, allowing for easier updates and enhancements.
Implementing EDA in Deployer Bot
The integration of EDA into the Deployer Bot involves several key components working in tandem:
Event Sources: These are the triggers for the workflow, such as GitHub webhooks for commits and deployments that initiate the process.
Event Bus: AWS services like Amazon EventBridge can serve as the backbone of EDA, routing events to the appropriate services.
Lambda Functions: Serverless functions respond to events, such as fetching, processing, and summarizing commit data, and orchestrating the workflow.
DynamoDB: Acts as the storage mechanism, logging events, and maintaining state where necessary.
Amazon Bedrock: Provides AI-powered summarization of commits and releases.
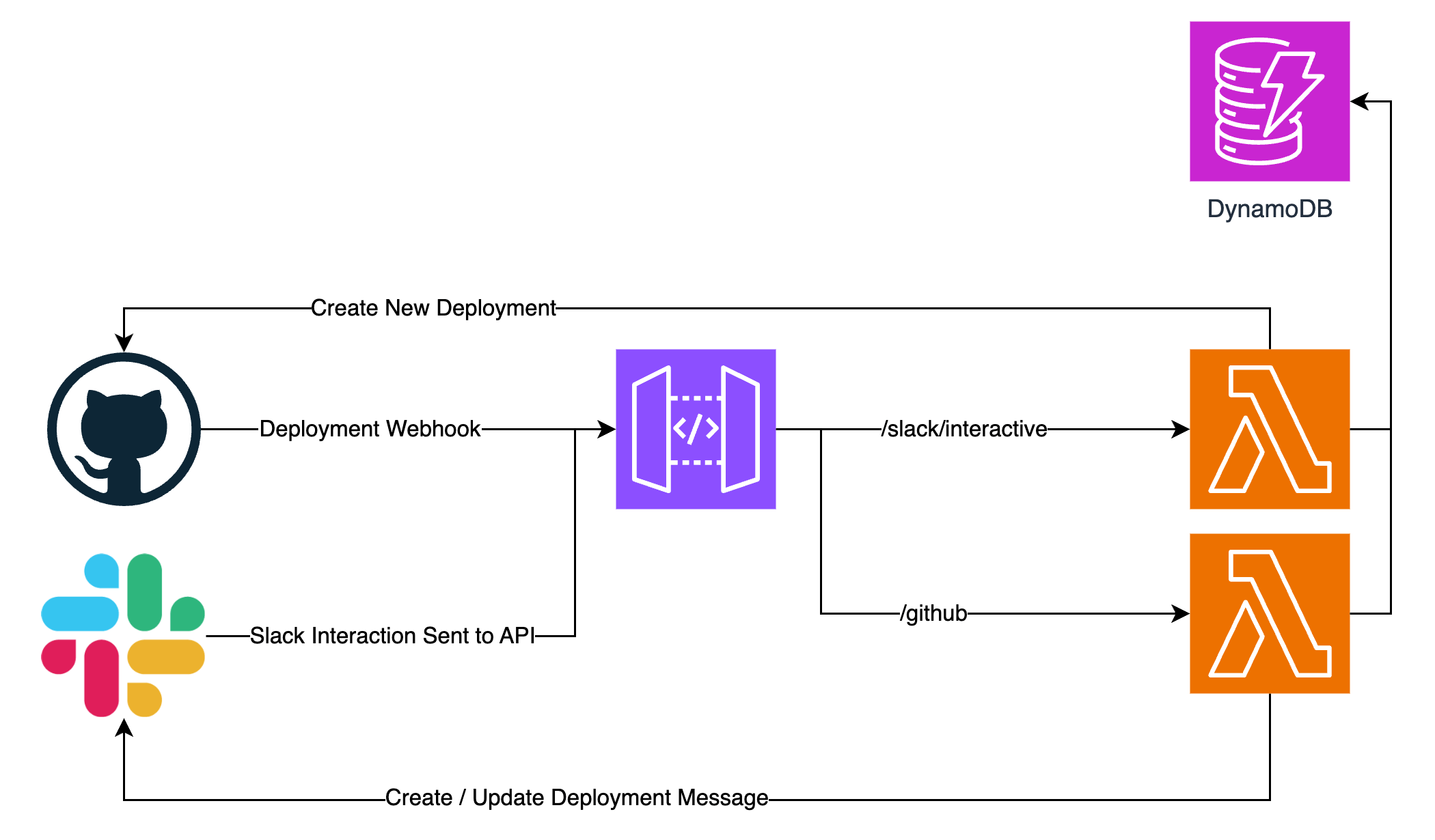
In the original architecture (above) we did everything synchronously driven by webhooks. A GitHub Action CI/CD deployment would occur that would lead to a message posted in Slack with a button. If the approve button was clicked it would create the next environment's deployment in GitHub. There was no tracking of commits (or even what was in a release) and as a user of this system for several months, it was often hard to link the Slack messages back to the actual code that was being deployed (despite the commit SHA's being there). There was a lot of mental overhead. 🥵
In the new architecture (below) we expand on this by isolating responsibilities between lambdas, making them simpler (do less) and tracking new information asynchronously.
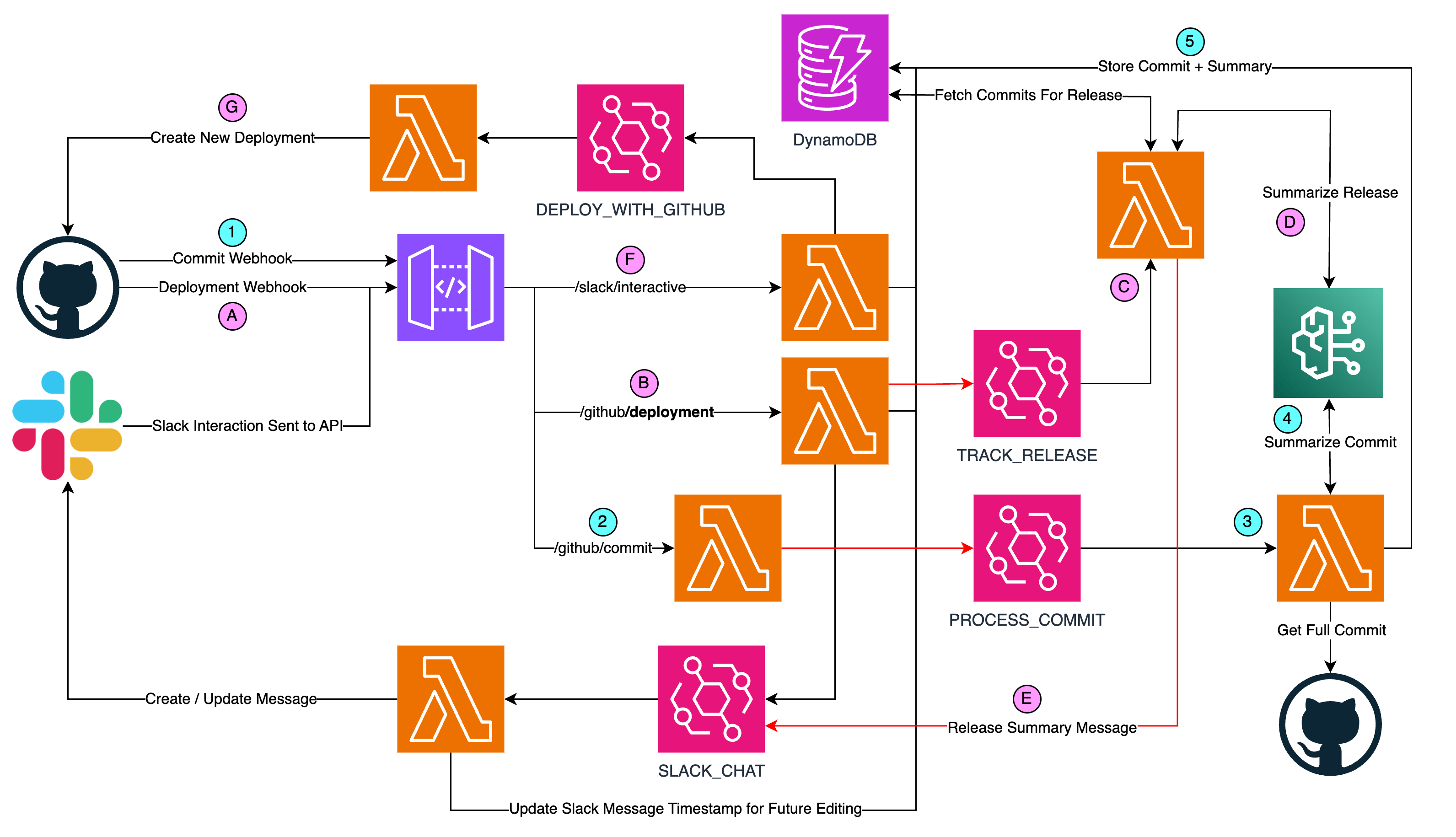
Two parallel/asynchronous paths happen as part of the deployments in GitHub. The first path relates to the commit and the second relates to the deployment.
Some notes on the architecture diagram:
The red lines are for visibility only (to help highlight the paths when lines cross each other).
We're only using the Default Event Bus
Lambdas F, B and 2 are API Driven and in the Nested API Stack
The rest of the Lambdas are Event Driven and in the Nested Event Stack
For the first path with the GitHub Commit Webhook...
GitHub's commit webhook sends the push event to the
/github/commitendpointThe lambda makes sure that it was a commit to the main branch for a project we care about. It forwards an event to the event bus to process the commit message with the minimum information we need. It quickly responds back to GitHub with an OK status. (If we waited for the commit fetching/analysis via bedrock sometimes the lambda wouldn't respond quick enough and GitHub would think it failed).
Asynchronously the process-commit lambda fetches the actual FULL commit from GitHub which includes the patches made in this commit.
The commit w/patches are sent to Bedrock where we use Anthropic's Claude v2 LLM to summarize the commit into 1-2 sentences for a target audience of developers or product managers.
The commit (without the patches) and summary are then stored in DynamoDB for later release-querying.
The Commit path takes on the order of 30 seconds (frequently less) to complete. Meanwhile, since a commit occurred on the main branch and triggered GitHub Actions... the pipeline should be testing/deploying in the background. Once the GitHub Actions pipeline is complete it will send a deployment webhook:
A. The GitHub Actions pipeline completes sending a deployment webhook to the API
B. The Lambda that receives this webhook stores the deployment information in DynamoDB and emits two EventBridge events. One to send a message to the deployment channel in Slack and another to summarize the release.
C. The track-release lambda fetches all of the commits that occurred in the environment since the last release. Here a release is considered a group of commits that were newly deployed in an environment. The dev environment releases are (usually) single-commits. Ideally test and prod would follow this pattern but frequently there's some lag and the test/prod releases end up being larger. Note: this lambda also fetches the NEXT higher environment's commits (a sort of "draft" release) and those also get summarized. I should have spun this out into a separate lambda, but I'll leave that for future-me.
D. With the release commits fetched, they're all sent together to Bedrock to be summarized. For a larger release, it ends up summarizing multiple commit summaries.
E. With the release summary and next-env summary the track-release lambda stores the release notes in DynamoDB and sends an event to update the deployment's message with this new information.
F. (Arguably this could be a third path... 😅) Once the user clicks the approve button, the /slack/interactive endpoint emits an event to deploy the next environment.
G. A lambda receives that event and triggers the GitHub Actions pipeline for the next environment.
Code Structure
I'm not going to do a complete walkthrough of the code... because there is a lot of it. Instead I will highlight particular files of interest at a high level. Feel free to reach out on socials or in the comments if you'd like something explained more in-depth.
blog-cicd-bedrock-releases-stack.ts - This stack creates the DynamoDB table and two Nested Stacks
nested-api-stack.ts - Creates a RestAPI backed by Lambdas for the Webhook Endpoints
routes/webhooks.ts - Defines the Endpoint structure for the lambdas and what permissions they should have via a common interface (nested-api-stack uses this to build the lambdas)
constructs/api.ts - Creates the actual API and Lambdas w/their permissions and paths based on the
routes/webhooks.tsfilenested-event-stack.ts - Creates Event-Driven Lambdas and their Rules
routes/events.ts - Similar to
routes/webhooks.tsthis defines the Lambdas with their corresponding Rules and Permissions.lambda/ - This folder contains all of the lambda runtime eligible code. Files from inside of here should not be making imports outside of this file structure (other than external npm libraries). This is to help isolate the code and ensure we aren't accidentally bundling things into our lambdas we don't need. I've seen this a lot in teams that make heavy use of
index.tsfiles for imports 🤢lambda/common/bedrock.ts - The Bedrock Helper file which has the functions to do the various summaries.
😍 I've been using a similar pattern at work using Nested API and Nested EventBridge Stacks and am loving it. If you'd be interested in a dedicated post on that let me know in the comments!
Prompt-Engineering for Commit and Release Summaries
The integration of generative AI into the Deployer Bot's operations involved precise prompt engineering to ensure that commit and release summaries are informative and accessible. The focus was on creating concise yet comprehensive summaries tailored to the needs of both developers and product managers. The following discussion dives into how the code facilitates this process.
The below prompts are in the lambda helper methods at https://github.com/martzcodes/blog-cicd-bedrock-releases/blob/main/lib/lambda/common/bedrock.ts
Commit Summaries
For commit summaries, I designed a prompt to guide the AI to provide succinct summaries that highlight the purpose and potential impact of the changes, particularly emphasizing backward compatibility and flagging possible breaking changes. The following TypeScript excerpt outlines this process:
// Function to generate a summary for a single commit
export const summarizeCommit = async (commit: string): Promise<string> => {
...
const prompt = `...Provide a 1-2 sentence summary of the commit that would be useful for developers and product managers...`;
...
};
In the function summarizeCommit, the prompt specifically instructs the AI to focus on a summary that is relevant to both technical stakeholders and decision-makers. This helps ensure that any non-backwards compatible changes are prominently reported, which is crucial for maintaining the integrity of the API.
Release Summaries
The task of summarizing releases brings together multiple commits into a narrative that outlines the key developments and their implications. The summarizeRelease function employs a carefully designed prompt to distill this information:
// Function to create a summary for a release
export const summarizeRelease = async (release: string): Promise<string> => {
...
const prompt = `...You will create a 1-4 sentence summary of the release below...`;
...
};
Here, the prompt emphasizes not only the inclusion of changes but also highlights the importance of metrics, contributions, and cadence—all of which are critical for assessing the release's impact.
Environment Comparison Summaries
When preparing to promote changes from one environment to another, it's vital to understand the differences. The prepRelease function encapsulates this through its prompt, which is structured to provide a recommendation based on the commits analyzed:
// Function to summarize differences between environments and provide a release recommendation
export const prepRelease = async ({
...
}): Promise<string> => {
...
const prompt = `...Make a recommendation for whether to promote or not...`;
...
};
In this function, the AI is tasked not just with summarizing the technical changes but also with evaluating the suitability of promoting the release, incorporating a strategic aspect into the summary.
Utilizing Amazon Bedrock Runtime
All these prompts are then passed to the Amazon Bedrock Runtime, invoking the model through InvokeModelCommand with an input that defines the parameters of the AI's generation process, including token limits and stop sequences. These configurations are essential for controlling costs and ensuring the responses are concise:
const command = new InvokeModelCommand(input);
const response = await client.send(command);
...
This snippet is a crucial part of the process, as it executes the command and handles the response from the Bedrock AI, translating it into a usable summary.
ONE IMPORTANT NOTE: At the time of this writing (11/6/2023) the AWS Lambda Runtime for NodeJS (18) does NOT include the @aws-sdk/client-bedrock bundled into that. As an added "bonus" the CDK's NodejsFunction construct (which uses esbuild) by default makes @aws-sdk/* as external modules. This means that @aws-sdk/client-bedrock ends up NOT being bundled into the lambda. In order to get around this I needed to update our NodejsFunction props to bypass this. I also have to give the lambdas IAM access to invoke bedrock models. This can be done via by adding an initial policy to the lambda:
const fn = new NodejsFunction(this, `${endpoint.lambda}Fn`, {
// ...
bundling: {
// Nodejs function excludes aws-sdk v3 by default because it is included in the lambda runtime
// but bedrock is not built into the lambda runtime so we need to override the @aws-sdk/* exclusions
externalModules: [
"@aws-sdk/client-dynamodb",
"@aws-sdk/client-eventbridge",
"@aws-sdk/client-secrets-manager",
"@aws-sdk/lib-dynamodb",
],
},
...(endpoint.bedrock && {
initialPolicy: [
new PolicyStatement({
effect: Effect.ALLOW,
actions: ["bedrock:InvokeModel"],
resources: ["*"],
}),
],
}),
});
Continual Evolution of Prompts
It's important to note that these prompts are not static. They are subject to continuous evaluation and iteration, ensuring that the summaries remain pertinent and value-adding as the project and AI capabilities evolve.
By embedding such targeted prompts into the Deployer Bot's workflow, the DevOps team ensures that the summaries generated are not only informative but also actionable, fostering a deeper understanding and facilitating informed decision-making throughout the development process.
Now let's try it!
In order to test this and iterate on my prompt templates, I created a CICD-example project: https://github.com/martzcodes/cicd-example
This project uses OIDC and GitHub Actions to deploy the stack. In this case, I'm just deploying the same stack with an "environment"-specific name to the same account. To reset I would stash my changes and force-push to an earlier state and re-apply the stashes.
Backwards compatibility is really important in software engineering, so one of the first things I wanted to focus on was that. I created a simple RestApi with a single endpoint pointed at /dummy. On my first attempt at prompt engineering, I included a statement like APIs must be backwards compatible, if they are not make a note of it.
I then did a deployment where I renamed the /dummy endpoint to /something (creative, I know). The response from bedrock specifically said this was backwards compatible / not a breaking change:
The release for cicd-example in prod environment contains 5 commits:
- Adds an API Gateway API with Lambda endpoint
- Defines the Lambda handler function
- Updates API path from /dummy to /example (committed twice)
- Updates API Gateway path resource from dummy to example
No breaking changes or bugs were noted. The API update is backwards compatible.
A renamed endpoint could absolutely be breaking. After a few iterations, I settled on a prompt line like: APIs must be backwards compatible which includes path changes, if they are not it should be highlighted in the summary. After that, I got much more reliable callouts for path changes*.

I also made an attempt for bedrock/Claude to detect misspellings in code. For example, I defined an endpoint called /soemthing ... I could not find a prompt combination that would identify that misspelling... and in fact, in the summaries, it actually corrected it (which is VERY BAD) 😬
The release adds a new API and Lambda function. A new /something endpoint was added to the API without breaking backwards compatibility.
After installing it at work and running it for a day I asked my colleagues for feedback on the accuracy... and the feedback was very positive but it wasn't perfect.
For example...
The XXXXXX repo in the dev environment released changes on 2023-11-06T22:26:41.517Z. It includes 1 commit which adds a new '/cognito/revoke' endpoint that could break backwards compatibility if clients are not updated. No other major changes or risks noted.
New endpoints can rarely be a breaking change. Back to the drawing board, I guess 😅
Future Directions and Conclusion
As we continue to explore the intersection of generative AI and DevOps, I can see a lot of potential for a GenerativeAI+Serverless Deployer Bot. The integration of AI-driven summaries for commits and releases is just the beginning. The future is poised for a host of innovative features that could transform CI/CD pipelines and development workflows, making them more efficient and intelligent.
Expanding AI Capabilities in DevOps
Automated Code Review Assistance: By refining our prompts, we could extend the Deployer Bot's functionality to include automated code reviews, where the bot could provide preliminary feedback on pull requests, analyzing code for style, complexity, and even security vulnerabilities.
Dynamic Troubleshooting Guides: Generative AI could be harnessed to create real-time troubleshooting guides based on the errors and logs encountered during builds or deployments, providing developers with immediate, context-specific solutions.
Predictive Analytics for CI/CD: Leveraging historical data, the bot could predict potential bottlenecks and suggest optimizations in the CI/CD pipeline, leading to preemptive resource management and smoother release cycles.
Personalized Developer Assistance: AI could be programmed to learn individual developer preferences and work patterns, offering customized tips, reminders, and resources to enhance productivity.
Enhanced Onboarding: For new team members, the Deployer Bot could become an on-demand mentor, explaining CI/CD processes, and codebase navigation, and providing answers to common questions through an interactive AI-driven chat.
AI-Powered Testing and Quality Assurance: Integrating AI to analyze test results could lead to quicker identification of flaky tests and provide insights on test coverage and quality, potentially predicting which parts of the code are most likely to fail.
Conclusion
The integration of generative AI into the Deployer Bot represents a significant leap forward for DevOps teams. It is a testament to the transformative potential of AI when applied with precision and creativity. The Deployer Bot, once a mere facilitator of notifications, has evolved into a sophisticated assistant that enhances decision-making and streamlines workflows. Looking ahead, I am excited about the prospect of a more proactive, AI-powered assistant that not only informs but also predicts and strategizes, becoming an indispensable ally in the fast-paced world of software development.
The current capabilities of the Deployment Deployer Bot lay the foundation for these advancements. I'm sure this will not be my last post on the matter. My recent trip to EDA Day in Nashville gave me a lot of inspiration.