





Two years ago The Burning Monk (AWS Hero Yan Cui) wrote a post about the differences between using a loosely coupled event driven architecture (choreography) vs tightly coupled step functions (orchestration) for micro service architectures. This was before Step Functions released their integrations with AWS services (which happened a year later in 2021). This two part series will explore how to combine the two by "Orchestrating Choreography" with event driven step functions.
In Part 1 of this two part series we'll use AWS CDK to make purely event driven step functions. A purely event driven step function is a step function that uses EventBridge events via the optimized EventBridgePutEvents step function task. It emits the event and will wait for a response that has the appropriate task token. Being event driven enables us to future-proof our workflows making them decoupled, scalable and eventually consistent by prioritizing only the critical path steps. By relying on EventBridge events we're able to spawn off "side effects" for non-critical path / long-running / async work. This also easily works cross-account and between different code repos since it relies on the default event bus (and not a bunch of step function permissions).
In Part 2 we'll focus on observability for all of the events, including the ones that the state machine doesn't track like side effects, intermediate events, and cross-account events (which AWS X-Ray doesn't handle very well). Observability was a big downside that the The Burning Monk highlighted and with some clever architecture I think we can overcome it.
Update: 7/29 - I have pushed some tweaks to the repo to help with the part 2 post so there might be slight differences between what you see in the article and what's in the repo. They're mostly cosmetic changes / nothing that changes the overall structure.
Overview
In this post we'll be using:
- 5 lambdas
- 2 state machines
- 1 event bus
- 1 S3 bucket
with a combination of:
The step function will emit an event to get a list of things to process, fan out the response using Step Function's Map to individual events that have an intermediate step and side effect, and then fan in to post-process everything.

I've used this type of structure at work to do cross-account data migrations. The migration would fetch a list of user groups, fan out to export the group from Aurora to S3... cross-account migrate from S3 to DynamoDB, and then output a report with the number of records moved / any validation errors. An async side-effect also moved files from one account's S3 bucket to the final account's S3 bucket.
A benefit of this type of structure is that you can pass around information between steps without having to necessarily add it into the Step Function's state. Step Functions have a state size limit of 256kb, which seems like a lot, but if you're processing a lot of data and passing around things like presigned S3 urls you will end up hitting that limit fairly quickly.
In the architecture diagram above we'll be doing just that! The "Post-Process Single" event will include a presigned url created from the "Process Single" lambda function.
We'll be making a fictional service that gets a list of names, retrieves information about those names, determines the number of cookies they've eaten, and then sums up the number of cookies they all ate into a cookie report. We'll be using the faker library for the user data.
Starting from Scratch
If you're starting from scratch, you can use the cdk CLI to create the project and install the needed dependencies:
npx cdk@2.x init --language typescriptnpm install -D @types/node-fetch @types/aws-lambda esbuildnpm i --save node-fetch @faker-js/faker aws-sdk
Creating a Level 3 (L3) Construct for the event bus
Since we're relying on EventBridge events for doing the actual work in our project, we're going to need a reliable way of accessing the default event bus and adding the necessary rules and environment variables for the lambdas. L3 constructs are a useful way to do this, so we'll be starting out by creating a L3 construct in bus.ts.
The constructor of this class simply retrieves the default bus
constructor(scope: Construct, id: string, props: BusConstruct) {
super(scope, id);
this.defaultBus = EventBus.fromEventBusName(this, `defaultBus`, "default");
}
Since we want to add similar rules for a bunch of lambdas, we can add a method on the class that does it for us (and consistently)
addLambdaRule(
id: string,
props: {
lambda: NodejsFunction;
eventPattern: EventPattern;
}
) {
new Rule(this, id, {
description: id,
eventBus: this.defaultBus,
targets: [new LambdaFunction(props.lambda)],
eventPattern: props.eventPattern,
});
this.defaultBus.grantPutEventsTo(props.lambda);
props.lambda.addEnvironment("EVENT_BUS", this.defaultBus.eventBusName);
props.lambda.addEnvironment("EVENT_SOURCE", SourceType.PROJECT);
}
This takes in an id for the rule, grants putEvents to the lambda, and adds EVENT_BUS and EVENT_SOURCE environment variables so the lambda knows the name of the bus (which in our case is "default" anyways but is a good practice in the event you need to use a non-default bus).
In our main stack we'll create the bus using the L3 construct and store it as a property on the stack:
this.bus = new Bus(this, `Bus`, {});
Creating the Bucket and Lambdas
Next, we're going to want a S3 Bucket to store intermediate files and an final report in. We'll create that in our main stack
const bucket = new Bucket(this, `Bucket`, {
autoDeleteObjects: true,
removalPolicy: RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
});
In our bucket we're blocking public access and making sure that when the stack is destroyed the bucket will be emptied and removed. autoDeleteObjects ends up creating a CustomResource on the stack that will get triggered when the stack is destroyed and will automatically empty the bucket. Bucket's can't be removed if they have items in them.
Now I'd like to add a method to the Stack's class that creates a lambda. We'll need 5 lambdas and all of them will get invoked by rules and some of them will need access to the Bucket we created.
addLambda({name, detailType, bucket}: { name: string, detailType: string, bucket?: Bucket}) {
const fn = new NodejsFunction(this, `${name}Fn`, {
logRetention: RetentionDays.ONE_DAY,
runtime: Runtime.NODEJS_16_X,
entry: `${__dirname}/lambda/${name}.ts`,
});
this.bus.addLambdaRule(`${name}Rule`, {
lambda: fn,
eventPattern: {
detailType: [detailType],
}
});
if (bucket) {
bucket.grantReadWrite(fn);
fn.addEnvironment("BUCKET", bucket.bucketName);
}
return fn;
}
This creates the lambda with log retention set to one day and optionally grants read/write access to the bucket along with adding an environment variable BUCKET for the bucket's name.
Now we can call this in our constructor to add the 5 lambdas:
this.addLambda({ name: `getMultiple`, detailType: DetailType.GET_MULTIPLE});
this.addLambda({ name: `processSingle`, detailType: DetailType.PROCESS_SINGLE, bucket});
this.addLambda({ name: `postProcessSingle`, detailType: DetailType.PROCESS_SINGLE_POST, bucket});
this.addLambda({ name: `postProcessAll`, detailType: DetailType.PROCESS_ALL, bucket});
this.addLambda({ name: `sideEffect`, detailType: DetailType.PROCESS_SINGLE_POST});
getMultipledoesn't need bucket accessprocessSinglewrites to s3 and creates a presigned urlpostProcessSinglereads from the presigned url and writes to s3sideEffectdoesn't need bucket access because it only reads using the presigned urlpostProcessAllreads from s3 (not via presigned urls) and writes to s3
Now let's write the lambdas...
Lambda: getMultiple
The getMultiple lambda will use the faker library to return a list of names to be processed in the subsequent map.
let ebClient: EventBridge;
export const handler = async (
event: EventBridgeEvent<string, any>
): Promise<void> => {
if (!ebClient) {
ebClient = new EventBridge();
}
// generate a random number of fake names from a "database"
await putEvent(ebClient, {
DetailType: DetailType.TASK_FINISHED,
Detail: JSON.stringify({
...event.detail,
names: Array.from({ length: Math.floor(Math.random() * 20) }, () =>
faker.name.findName()
),
}),
});
};
All this does is cache the EventBridge client and put a random-sized list of random names to be processed and emits them in the event. It doesn't store anything and as matter of practice we know we won't exceed the state size limit. If you needed to process a large dataset that ran the risk of going over 256kb, then you'd probably want to store this in s3.
Lambda: processSingle
The processSingle lambda is after the map, so it will expect to process a single name from the list generated in the step before.
const name = event.detail.name;
// here we're looking up the person's profile
// maybe this hits a 3rd party API? maybe it's querying a legacy database?
const profile = {
name,
company: faker.company.companyName(),
city: faker.address.cityName(),
};
const s3Params = {
Bucket: process.env.BUCKET,
Key: `${event.detail.execution}/basic-${name}.json`,
};
await s3
.putObject({
...s3Params,
ACL: "bucket-owner-full-control",
Body: JSON.stringify(profile, null, 2),
} as PutObjectRequest)
.promise();
const presigned = await s3.getSignedUrlPromise("getObject", {
...s3Params,
Expires: 15 * 60,
});
if (!ebClient) {
ebClient = new EventBridge();
}
await putEvent(ebClient, {
DetailType: DetailType.PROCESS_SINGLE_POST,
Detail: JSON.stringify({ ...event.detail, profile: presigned }),
});
The lambda expects the name to be in the event's detail. When it execute it generates a profile for that person (maybe this would hit a 3rd party API or a database) and then we save the profile to S3 and generate a presigned url for other lambdas to use. The event from this lambda will end up being used by postProcessSingle and sideEffect
Lambda postProcessSingle
The postProcessSingle lambda for the demo's simplicity this lambda is essentially the same as the processSingle lambda, it just adds one more piece of information to the profile numberOfCookiesConsumed and saves it to S3. It does not generate a presigned url though (but it could).
Lambda: sideEffect
The sideEffect lambda doesn't really do anything other than emit an event. Since this is a side-effect it could be a long-running process or something that kicks off other state machines, sends out a notification, updates 3rd parties / etc. I've used this to trigger an eventually consistent copy from one s3 bucket to another.
Lambda: postProcessAll
After all of the maps are complete, the postProcessAll lambda reads all the files (at known paths) from the list that getMultiple output that was saved to the step function's state and sums up all the numberOfCookiesConsumed for all the people. It then writes this to s3 in a file called 0-cookies.json.
Creating a L3 Construct for the state machines
Finally... let's create the event driven state machine. The state machine will have 3 main steps and a final "Succeed" step.
The EventBridgePutEvent steps will have some common items between them and we can save a little code if we add a private method to the L3 Construct:
private createEvent(
id: string,
{
eventBus,
detailType,
details,
resultPath,
}: {
eventBus: IEventBus;
detailType: DetailType;
details: Record<string, string>;
resultPath?: string;
}
): EventBridgePutEvents {
return new EventBridgePutEvents(this, id, {
entries: [
{
detail: TaskInput.fromObject({
...details,
TaskToken: JsonPath.taskToken, // this is required for WAIT_FOR_TASK_TOKEN
}),
eventBus,
detailType,
source: SourceType.PROJECT,
},
],
...(resultPath
? {
resultSelector: TaskInput.fromJsonPathAt(resultPath),
resultPath,
}
: { resultPath: JsonPath.DISCARD }),
integrationPattern: IntegrationPattern.WAIT_FOR_TASK_TOKEN,
});
}
Not all of the events will have something stored in the state. When we don't want them saved we'll set resultPath: JsonPath.DISCARD... this will pass through the input of the step to its output.
With that in place we can create the three steps.
// 1st step - get multiple
const multipleEvent = this.createEvent(`GetMultiple`, {
details: {
"execution.$": "$$.Execution.Id", // this is the arn for the state machine running
},
resultPath: "$.names",
detailType: DetailType.GET_MULTIPLE,
eventBus: props.bus.defaultBus,
});
This will emit the detail type needed for the getMultiple lambda and include the state machine's execution id (which is the ARN for the state machine being run). All of our steps will have this.
The next step will map out the response from getMultiple and invoke the detail type needed for processSingle. Note we're NOT emitting events from the state machine for either postProcessSingle or the sideEffect.
// 2nd step - fan out: map -> process-single -> post-process-single
// only emits the event to trigger process-single... process-single emits event to trigger post-process-single
// post-process-single emits task finished event which closes out the step with the task token
const processSingleEvent = this.createEvent(`ProcessSingle`, {
details: {
"name.$": "$.name",
"execution.$": "$.execution", // this is the arn for the state machine running, provided via the map params
},
detailType: DetailType.PROCESS_SINGLE,
eventBus: props.bus.defaultBus,
});
const mapToSingle = new Map(this, `ProcessMultiple`, {
maxConcurrency: 2,
itemsPath: "$.names.value", // due to the multi-state machine finisher the names end up in a value object
parameters: {
"name.$": "$$.Map.Item.Value", // this is an item in the list provided via the items path
"execution.$": "$$.Execution.Id", // this is the arn for the state machine running
},
resultPath: JsonPath.DISCARD,
});
mapToSingle.iterator(processSingleEvent);
We have the maxConcurrency set to 2... this means that if there are 10 names being fanned out, it'll do 2 at a time. Once one name is fully processed another name will start processing (it doesn't do them in batches of 2).
We also tell the map that the thing we want to iterate on is $.names.value. This becomes $$.Map.Item.Value in the parameters as name. The processSingleEvent takes this and adds it to the detail as name. When assigning values in a JSON object if you're using JsonPath for the value (meaning it's being retrieved from the state)... you postfix the key with .$. Here, you see we're setting name.$ to $$.Map.Item.Value in the Map, and the iterator (processSingleEvent) is re-casting this to the EventBridge event's detail using "name.$": "$.name". In the lambda you can see this accessed as event.detail.name without any dollar signs.
Finally we create the postProcessAll step and tie them all together ending in a success.
// 3rd step - fan in: post-process-all
const postProcessAll = this.createEvent(`PostProcessAll`, {
details: {
"names.$": "$.names.value", // matches the resultPath of the getMultiple step
"execution.$": "$$.Execution.Id", // this is the arn for the state machine running
},
detailType: DetailType.PROCESS_ALL,
eventBus: props.bus.defaultBus,
resultPath: "$.totalCookiesConsumed"
});
// success
const success = new Succeed(this, `Success`);
const definition = multipleEvent
.next(mapToSingle)
.next(postProcessAll)
.next(success);
this.stateMachine = new StateMachine(this, `EventdrivenMachine`, {
definition,
});
In order to start the state machine, we could execute it via the console but it would be nice to have a CLI invoke option. Since everything else is event driven, we can also create a rule that a certain "start" event could invoke the state machine:
new Rule(this, `StartMachineRule`, {
eventBus: props.bus.defaultBus,
eventPattern: {
detailType: [DetailType.START],
},
targets: [new SfnStateMachine(this.stateMachine)]
});
The Task Finisher State Machine
You may have noticed earlier that I mentioned we need two state machines. Unfortunately there isn't an EventBridge target option to give a state machine "response" (i.e. doing the callback token to complete a step). So we have (at least) two easy options... use a lambda to call the step function SDK to close out the task OR we could use an express step function. The benefit of an express step function is that there isn't a cold start associated with it and it has a CallAwsService step built-in (no lambda needed).
const taskSuccess = new CustomState(this, `TaskSuccess`, {
stateJson: {
Type: "Task",
Resource: `arn:aws:states:::aws-sdk:sfn:sendTaskSuccess`,
Parameters: {
"Output.$": "$.detail",
"TaskToken.$": "$.detail.TaskToken",
},
},
});
const finisherMachine = new StateMachine(this, `StepFinisher`, {
definition: taskSuccess.next(new Succeed(this, `TaskSucceeded`)),
timeout: Duration.minutes(5),
});
this.stateMachine.grantTaskResponse(finisherMachine);
new Rule(this, `FinisherRule`, {
eventBus: bus.defaultBus,
eventPattern: {
detailType: [DetailType.TASK_FINISHED],
},
targets: [new SfnStateMachine(finisherMachine)],
});
This is a very simple state machine that is always triggered on a TASK_FINISHED detail type where it simply passes through the event detail's TaskToken through to the Step Function SDK.
Adding the EventdrivenStepfunction L3 Construct
We can add the EventdrivenStepfunction construct to our stack using new EventdrivenStepfunction(this,SM, { bus: this.bus });.
Running the State Machine
Now, once we npx cdk deploy we'll be able to trigger our State Machine via the CLI or via events. Via CLI you could use aws events put-events --entries Source=project,DetailType=start,EventBusName=default,Detail=\"{}\" --region us-east-1.
If you were to log into the console you'd be able to track the progress over the State Machine's steps with it resulting in:
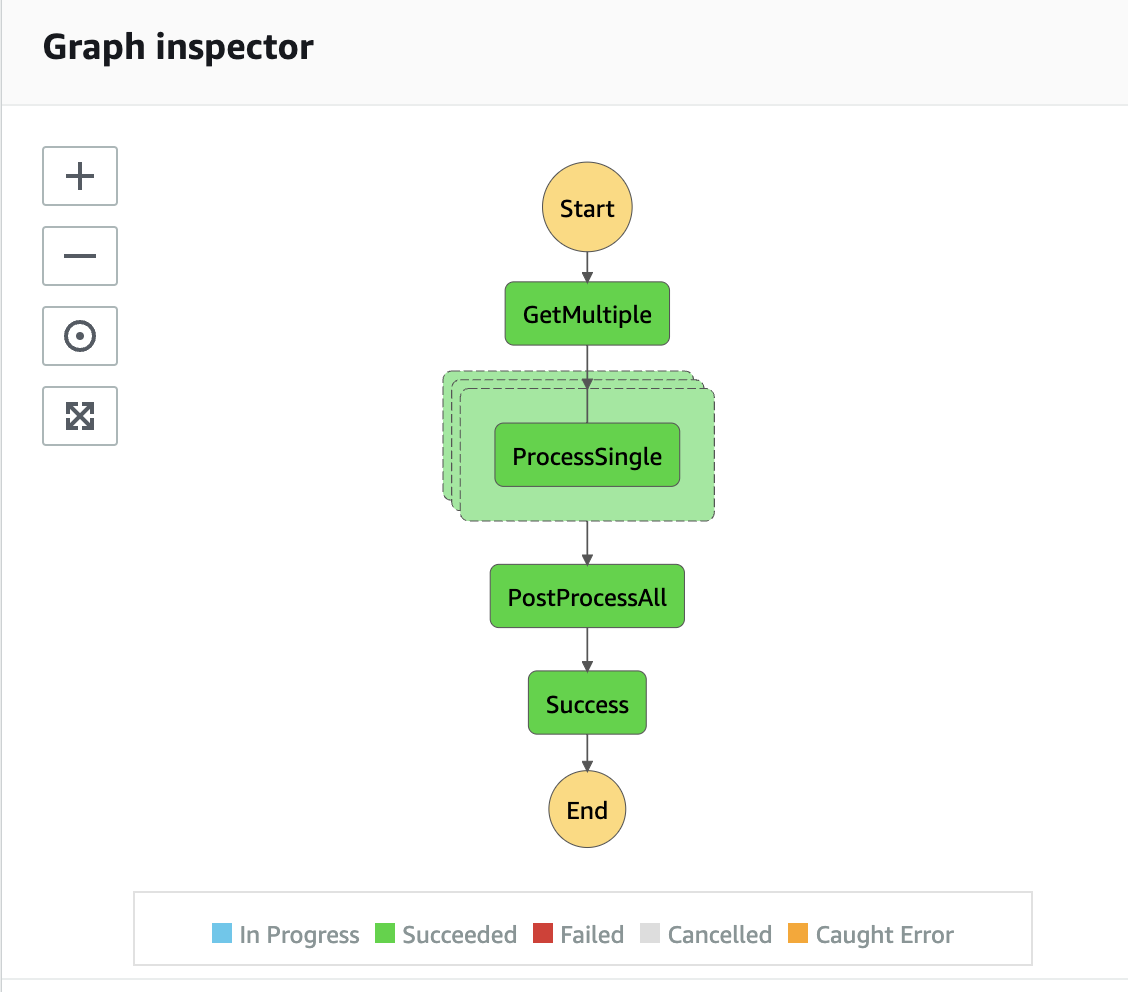
Using cdk-app-cli you could open up the S3 bucket's console with npx cdk-app-cli Bucket visit-console where you'd see
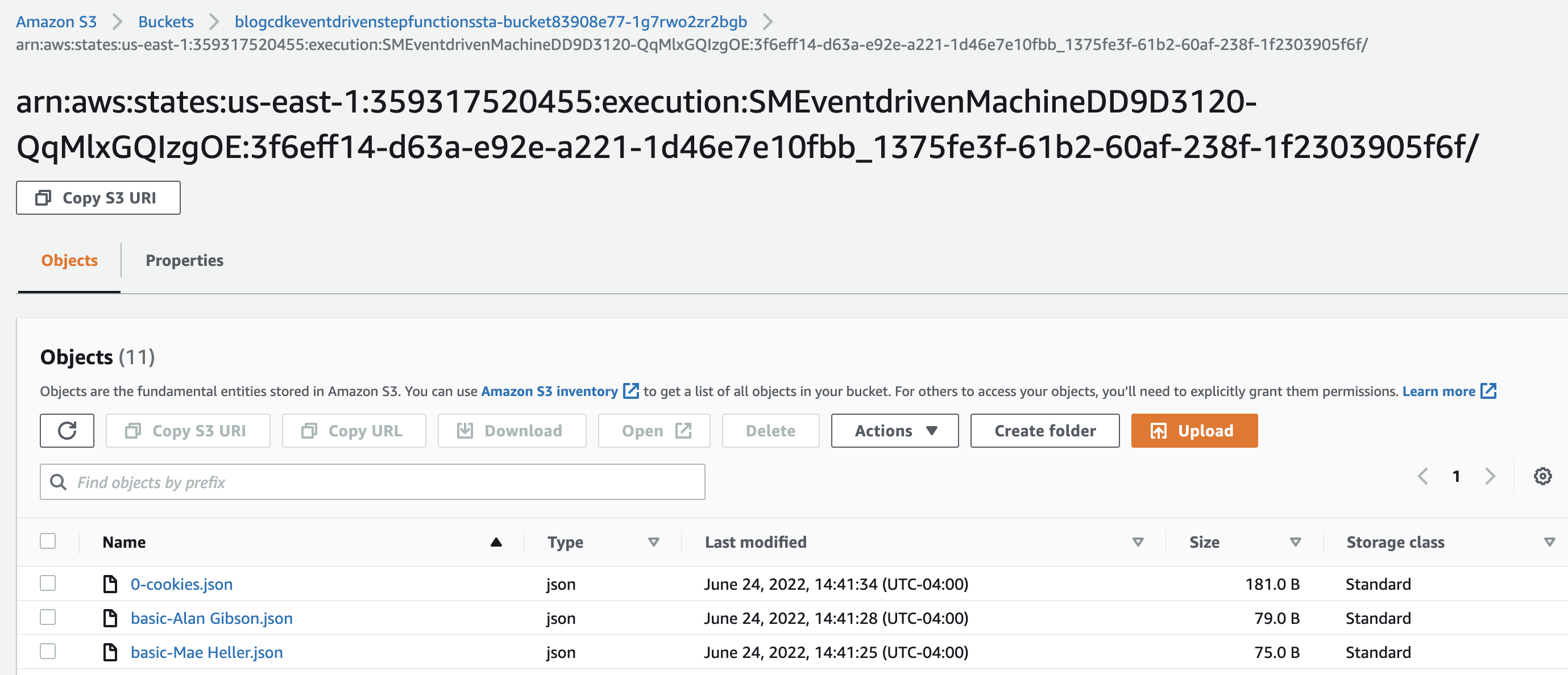
and if you download the 0-cookies.json file you'd have something like
{
"names": [
"Roberta Mills",
"Mae Heller",
"Alan Gibson",
"Mrs. Heather West",
"Mr. Marcia Labadie"
],
"numberOfPeople": 5,
"totalCookiesConsumed": 25
}
In this test run through it generated 5 people that combined at 25 cookies. With subsequent runs of the step function you'd get random results from the faker library.
Conclusion
Running workflows driven by EventBridge events can be really powerful. You can build rich async processes via the events that are decoupled from one another enabling multiple teams to interact with the same event structure without getting in each others way. You can also share events between different step functions while ensuring that your data is consistently processed.
In part 2 of this series we'll focus on the observability of EventBridge events / jobs including things outside of the step functions (intermediate steps / async side-effects).