

Using GitHub's API to search for code references across multiple organizations


Background
As part of a modernization project we're trying to split up our ~900 table MySQL database into much fewer DynamoDB tables. In order to evaluate this, we need to analyze the impact to our code. Easy enough, right? Well... we have two GitHub organizations with a combined 800 repos to look through.
To help with this, I wrote a script to do code searches with GitHub's v3 API.

Pre-reqs
You'll need a personal access token with Read access defined in your environment variables under GITHUB_CREDENTIALS_PSW.
I have Node version v12.13.1 installed.
Example code is here:
{% github martzcodes/code-reference-search no-readme %}
There are only 3 dependencies installed into the project... Node types, typescript and axios.
A search.json file also needs to be created. The JSON object includes a list of code strings to search for and the GitHub organizations to search through.
In the example I just did a basic search for password across a couple larger organizations... don't read into that... I just knew it'd be a common thing mentioned in at least one place.
In my actual use case the list of code strings I used were the table names. For 32 tables x 2 organizations this will be 64 API calls (which is over the authenticated user's rate limit of 30 / minute... more on that later.
The Script
The script is fairly straight-forward. First I do the imports and initialize the reporting object.
const fs = require("fs");
const axios = require("axios");
const searchData = require("./search.json");
// personal access token stored in env
const githubReadApiKey = process.env.GITHUB_CREDENTIALS_PSW;
const findings: any = {
repos: {},
code: {},
};
Then I have some helper functions... this simply makes setTimeout a Promise so I can use it asynchronously later.
async function sleep(ms: number) {
return new Promise((resolve) => setTimeout(resolve, ms));
}
This getRateLimit function isn't specifically used but is useful for testing. Authenticated API calls are allowed to make 30 searches per minute... BUT it turns out GitHub also does abuse detection.
async function getRateLimit() {
return axios.get("https://api.github.com/rate_limit", {
headers: {
Authorization: `token ${githubReadApiKey}`,
},
});
}
The searchCode function is the main API call that does the searching. I had to build in some multiple-attempt / wait code due to GitHub responding with You have triggered an abuse detection mechanism. Please wait a few minutes before you try again. on occasion (even when under the API rate limit for searching). Fortunately their docs include a way around this: developer.github.com/v3/guides/best-practic..

The response includes a retry-after header... which the script detects and waits for that time (typically a minute) + 1 second.
async function searchCode(codeStr: string, org?: string): Promise<SearchResults | null> {
const orgStr = org ? `+org:${org}` : "";
const attempts = 2;
for (let attempt = 0; attempt < attempts; attempt++) {
try {
const res = await axios
.get(
`https://api.github.com/search/code?q=${encodeURIComponent(
codeStr
)}${orgStr}&per_page=100`,
{
validateStatus: function () {
return true;
},
headers: {
Authorization: `token ${githubReadApiKey}`,
},
}
)
.catch((e: Error) => {
console.error(e);
});
if (res.status > 200) {
console.log(res.data.message);
const retryAfter = parseInt(res.headers["retry-after"]);
console.log(
`Sleeping for ${retryAfter + 1} seconds before trying again...`
);
await sleep((retryAfter + 1) * 1000);
} else {
return res.data;
}
} catch (e) {
console.error(e);
}
}
// shouldn't get here...
return Promise.resolve(null);
}
The results are then split up into what I think are useful metrics...
async function processResults(results: any, codeStr: string, org?: string) {
console.log(`${codeStr}: ${results.items.length} - ${results.total_count}`);
const items = results.items;
findings.code[codeStr].count =
findings.code[codeStr].count + results.total_count;
items.forEach((item: any) => {
if (
findings.code[codeStr].repos.indexOf(item.repository.full_name) === -1
) {
findings.code[codeStr].repos.push(item.repository.full_name);
findings.code[codeStr].repoCount = findings.code[codeStr].repos.length;
}
if (Object.keys(findings.repos).indexOf(item.repository.full_name) === -1) {
findings.repos[item.repository.full_name] = {
paths: [
{
path: item.path,
score: item.score,
url: item.html_url,
},
],
code: {},
codeCount: 1,
};
findings.repos[item.repository.full_name].code[codeStr] = 1;
} else {
findings.repos[item.repository.full_name].paths.push({
path: item.path,
score: item.score,
url: item.html_url,
});
if (
Object.keys(findings.repos[item.repository.full_name].code).indexOf(
codeStr
) === -1
) {
findings.repos[item.repository.full_name].code[codeStr] = 1;
findings.repos[item.repository.full_name].codeCount = Object.keys(
findings.repos[item.repository.full_name].code
).length;
} else {
findings.repos[item.repository.full_name].code[codeStr] =
findings.repos[item.repository.full_name].code[codeStr] + 1;
}
}
findings.repos[item.repository.full_name].pathCount =
findings.repos[item.repository.full_name].paths.length;
});
}
Finally... I use an async function to run all of these. I flatten the searches into one list, do the api calls in series with some post-processing and write it to an output.json file.
async function main() {
console.log("Starting Search...");
const flattenedSearches: string[][] = [];
searchData.codeStrings.forEach((codeStr: string) => {
searchData.organizations.forEach((org: string) =>
flattenedSearches.push([codeStr, org])
);
});
for (let searchInd = 0; searchInd < flattenedSearches.length; searchInd++) {
const search = flattenedSearches[searchInd];
const searchResults = await searchCode(search[0], search[1]);
findings.code[search[0]] = {
count: 0,
repos: [],
repoCount: 0,
};
processResults(searchResults, search[0], search[1]);
}
findings.priority = {
repos: Object.keys(findings.repos).sort(
(a, b) => findings.repos[b].pathCount - findings.repos[a].pathCount
),
code: Object.keys(findings.code).sort(
(a, b) => findings.code[b].count - findings.code[a].count
),
};
let data = JSON.stringify(findings, null, 2);
fs.writeFileSync("output.json", data);
console.log("Search Complete!");
}
main().catch((e) => console.error(e));
The Output
The output breaks things down into the repositories that were found, the code and a prioritization of what to look at (based on occurence.
repos... the repos foundrepos.<repo>.code... what code was in themrepos.<repo>.codeCountandrepos.<repo>.pathCountsome basic counts for readability
code... the original search termscode.<code>.repos... the repos found for that codecode.<code>.count... a count of "mentions"code.<code>.repoCount... the number of repos that code was found in
priority... prioritized lists of what to look at by count (start at the top of the list)
I generally find this to be enough data to do some further post-processing on to generate graphs such as this (from my actual data):
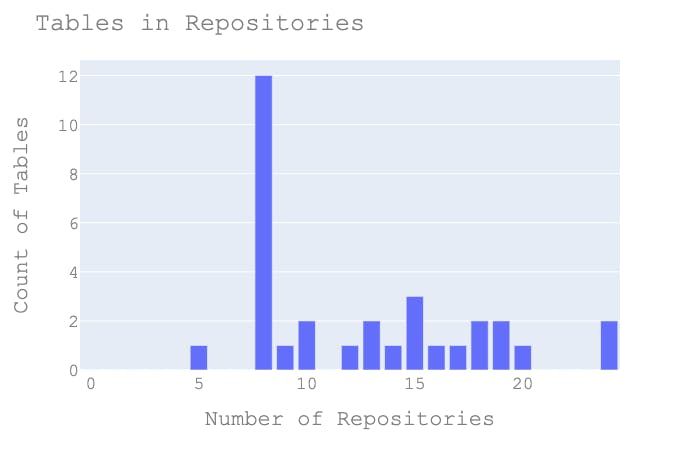
Unfortunately, this only searches for table names... not actual USAGE of them... so there's still a lot of data to go through.

If you have any useful tools for doing this type of refactoring analysis, let me know in the comments.