




Lately I've been encountering some issues with a particular architecture for propagating data changes between multiple AWS accounts. The current architecture relies on having DynamoDB Stream-invoked lambdas writing files into a "legacy" AWS account bucket which then triggers Lambdas to do the changes.
The real issue that we started seeing was when you have multiple developers spinning up the same multi-bucket architecture stack in the same AWS account you start getting close to (or hitting) AWS Account Bucket limits (which is 100, by default).
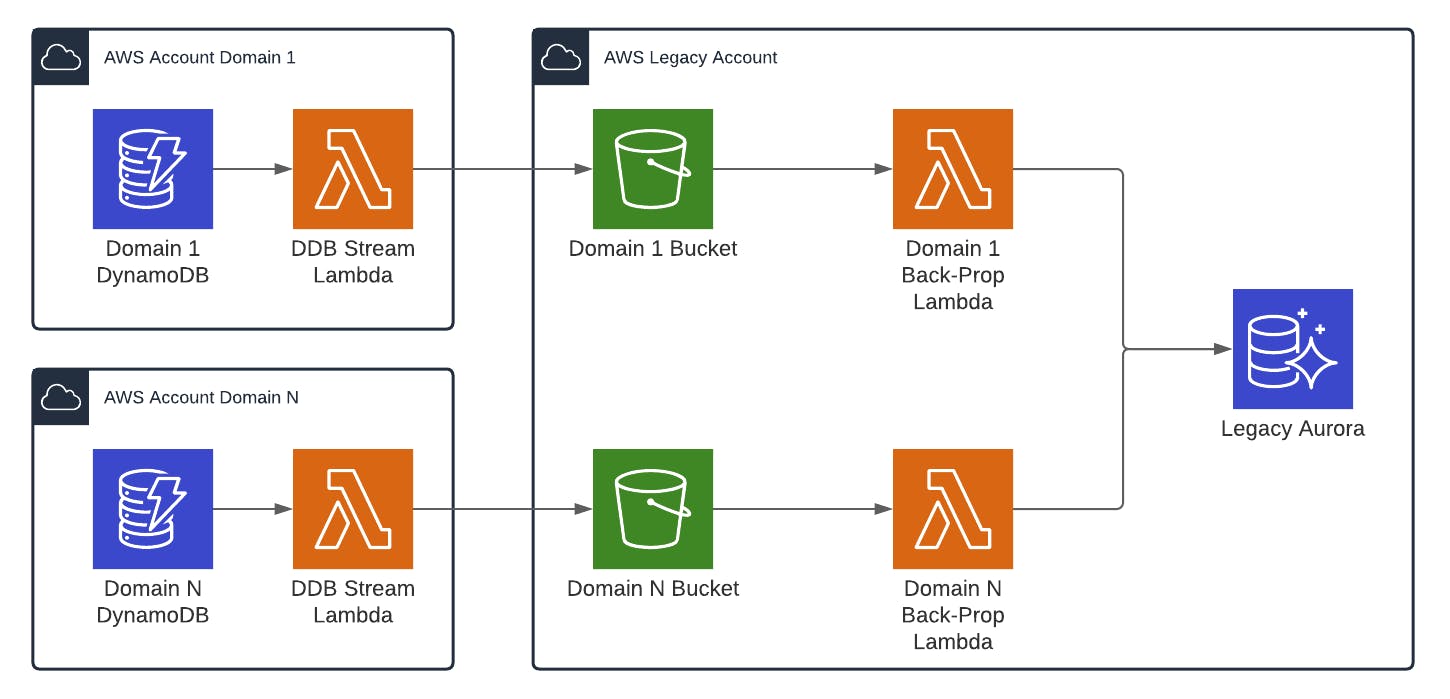
A basic CDK configuration for this would look like this:
// Repeat below via construct or copy-pasta
const domainOneBucket = new Bucket(this, 'domainOneBucket', {
accessControl: BucketAccessControl.BUCKET_OWNER_FULL_CONTROL,
bucketName: `martzcodes-domain-bucket-${ENVIRONMENT}`,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
removalPolicy: RemovalPolicy.DESTROY,
});
const domainOneFn = new NodejsFunction(this, 'DomainOneFunction', {
entry: '/path/to/domainOne.ts',
handler: 'handler'
});
domainOneBucket.grantRead(domainOneFn);
domainOneFn.addEventSource(
new S3EventSource(domainOneBucket, {
events: [EventType.OBJECT_CREATED],
}),
);
This setup works, but it's not ideal. It runs into a number of limitations fairly quickly.
- Each domain flow has its own bucket (inefficient)
- It's not very flexible. It's basically a poor-man's event driven architecture made with buckets (bucket driven architecture?)
An improvement on this would be to use a single bucket and then use prefix filters to invoke the lambdas.
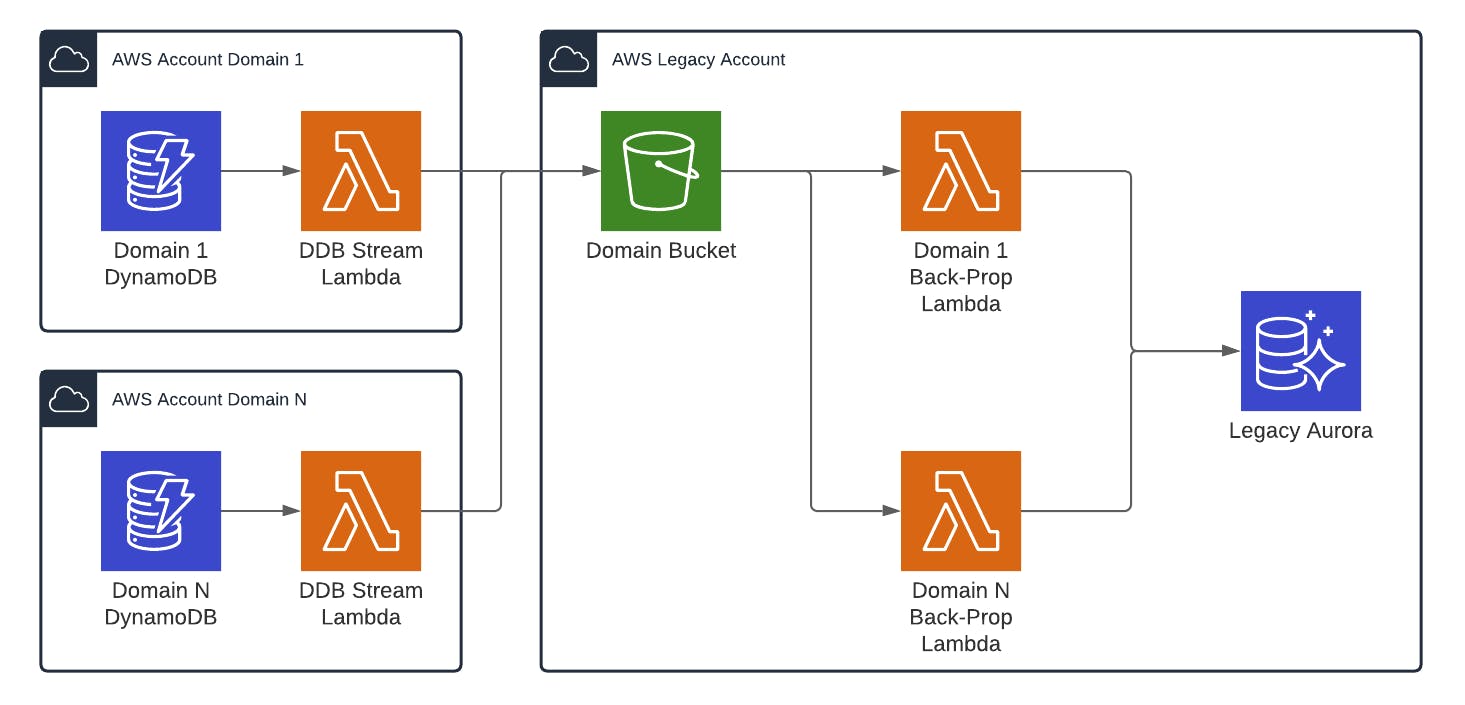
const combinedBucket = new Bucket(this, 'combinedBucket', {
accessControl: BucketAccessControl.BUCKET_OWNER_FULL_CONTROL,
bucketName: `martzcodes-combined-bucket-${ENVIRONMENT}`,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
removalPolicy: RemovalPolicy.DESTROY,
});
// Repeat below via construct or copy-pasta
const domainOneFn = new NodejsFunction(this, 'DomainOneFunction', {
entry: '/path/to/domainOne.ts',
handler: 'handler'
});
combinedBucket.grantRead(domainOneFn);
domainOneFn.addEventSource(
new S3EventSource(combinedBucket, {
events: [EventType.OBJECT_CREATED],
filters: [ { prefix: 'domainOne/' } ]
}),
);
This single-bucket approach alleviates the multi-bucket issue but still has the same lack of flexibility.
In my case all of these db change events are under the 256KB entry size constraint of EventBus payloads
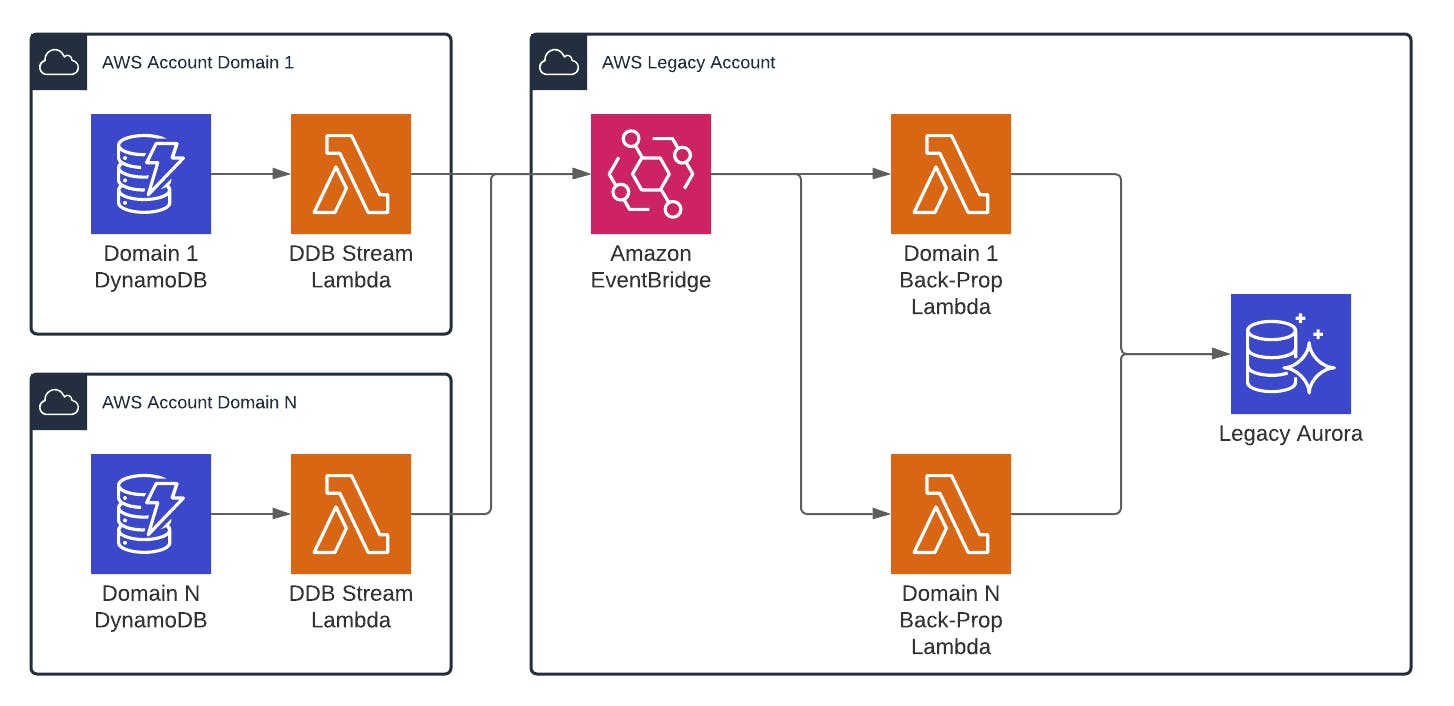
const bus = new EventBus(this, 'someBus', {
eventBusName: 'someBus',
});
// Repeat below via construct or copy-pasta
const domainOneRule = new Rule(this, 'domainOneRule', {
description: 'Domain One Lambda',
eventPattern: {
source: ['domainOne'],
},
eventBus: bus,
});
const domainOneFn = new NodejsFunction(this, 'DomainOneFunction', {
entry: '/path/to/domainOne.ts',
handler: 'handler'
});
domainOneRule.addTarget(new LambdaFunction(domainOneFn));
This solves the multi-bucket issue while providing MUCH more flexibility, since other things could easily make use of the same event bus. EventBridge also supports archival and replayability, which could be useful for troubleshooting. These events could also be discovered or defined with the EventBridge Schema Registry
The downside to this approach is the 256KB size limit of the event entry. If that ends up being an issue you could add the combined bucket back and pass a reference to it inside the event entry.
AppFlow actually does something similar (that I thought was a feature of EventBridge itself, but it seems to be AppFlow specific). When you create an AppFlow integration between EventBridge and a supported SaaS it asks you to create an S3 bucket to handle payloads larger than 256KB. I wonder if that'll get added as an EventBridge feature later 🤔