





Aurora MySQL doesn’t offer a change data capture stream similar to DynamoDB Streams. In this post we’re going to make one anyways by using the built-in MySQL BinLog file(s) and a scheduled lambda to parse it. We'll store this data in S3 where it could be used to trigger other workflows or Event Driven Architecture.
⚠️ This is an advanced post that expects some understanding of CDK (and MySQL to a certain extent). If you need a crash course on CDK check out my CDK Crash Course for freeCodeCamp.org If you're comfortable with CDK and MySQL and something isn't clear... feel free to hit me up on Twitter @martzcodes
Here is our target architecture:
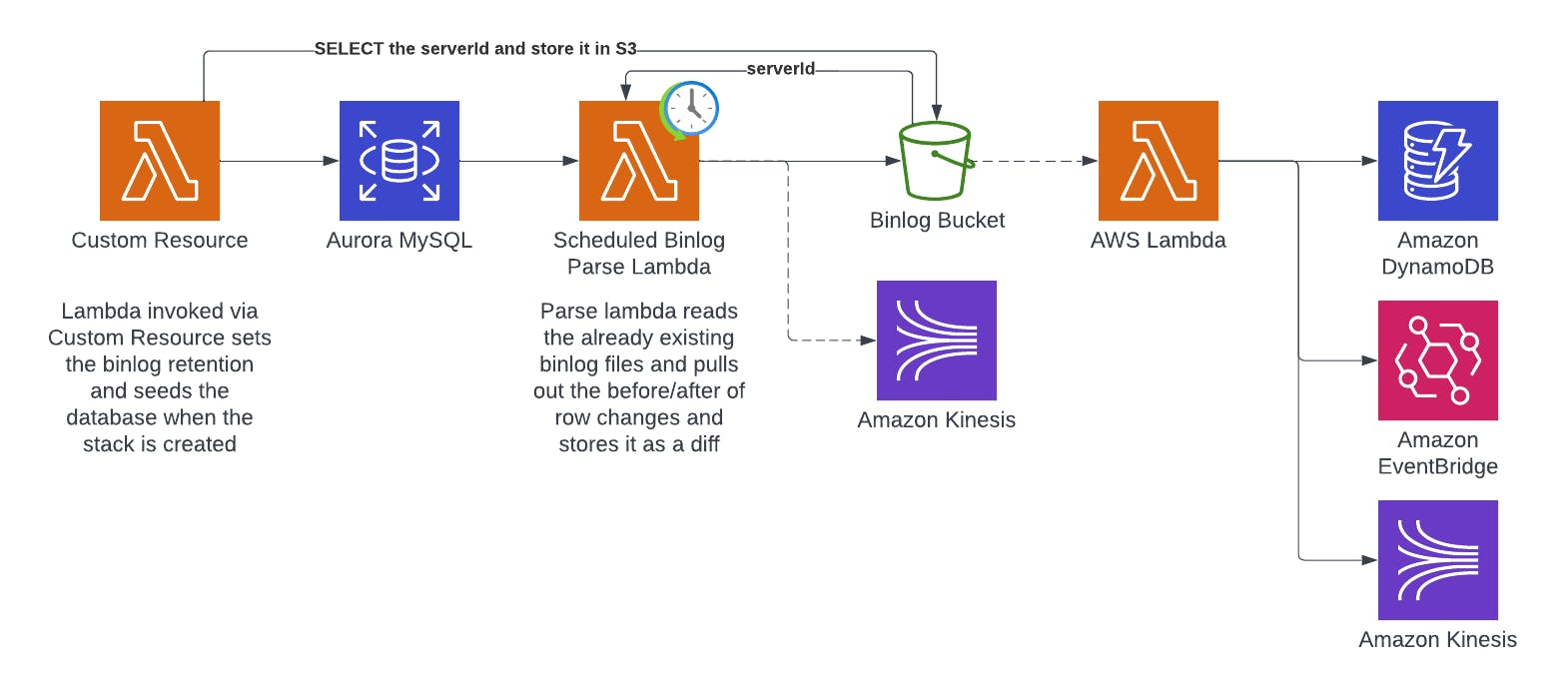
We'll be using CDK to provision all of our resources. There are a lot of options for what to do after parsing. We're storing to s3 so we can fan out / post-process... but you could go directly to kinesis (or any number of other things). The architecture diagram above shows some examples of this.
As part of this post we're only going to focus on:
- Creating the Database
- Initializing the Database via a Custom Resource (Lambda)
- Creating a Lambda to Parse the BinLog
- Storing the Parsed Events into S3*
If you're processing a lot of data make sure the events you emit don't slow down the processing. For example, in an initial test I was going from BinLog Parser -> DynamoDB, but doing put items for each individual row added a lot of latency and SIGNIFICANTLY decreased the number of records I could process. For example I was only able to process half of my data (~125k row events) over 15 MINUTES... vs ALL of the data (~250k row events) to S3 in 30 SECONDS 🤯
Code: github.com/martzcodes/blog-cdk-rds-binlog-s..
What is a BinLog File?
💡BinLog is short for binary log.
MySQL BinLogs are a built-in feature of MySQL (it isn’t Aurora/RDS specific). Any time a change happens in MySQL it is written to a binary log file. When using the “ROW” binlog_format the change event includes both the before and after snapshot of the row that changed. For database transactions that include changes to multiple rows… it stores each row individually in a single event. BinLogs are also chronological. Everything is ordered by the time of the event and the BinLogs are streamed in that same order. In the background binlog files have a maximum size (set via config) and when that size is reached it creates a new file. The server will retain these logs for a retention period configured in the database.
BinLogs are typically used for replication and data recovery. We’re going to use them for streaming change data events 😈
Binary logging can limit database performance (higher commit latency and lower throughput) because the logging for binlog events is integrated as part of a critical path of transaction commits.
Last year AWS released some cache improvements for binlog so you may want to turn those on as well.. But, if you already have binlogs turned on and aren't worried about the performance impact... an additional consumer of the binlog should add little overhead.
Creating the Database
ℹ️ We'll be creating a database from scratch using CDK, but this can also be used with an existing database. To use an existing database you'll need to make sure binlogs are turned on and outputing in ROW format. Then you'll need a database user with SELECT, REPLICATION CLIENT, REPLICATION SLAVE grants.
Database Clusters need a VPC attached to them, so our first step is to create a VPC:
const vpc = new Vpc(this, "Vpc");
From there we create the Database Cluster using that VPC:
const cluster = new DatabaseCluster(this, "Database", {
clusterIdentifier: `stream-db`,
engine: DatabaseClusterEngine.auroraMysql({
version: AuroraMysqlEngineVersion.VER_2_10_1,
}),
defaultDatabaseName: "martzcodes",
credentials: Credentials.fromGeneratedSecret("clusteradmin"),
iamAuthentication: true,
instanceProps: {
instanceType: InstanceType.of(
InstanceClass.T3,
InstanceSize.SMALL
),
vpcSubnets: {
subnetType: SubnetType.PRIVATE_WITH_EGRESS,
},
vpc,
},
removalPolicy: RemovalPolicy.DESTROY,
parameters: {
binlog_format: "ROW",
},
});
The important, binlog-related, part of this is that we're using the parameters property to set the binlog_format to ROW. This is the only change we need to make to the default MySQL parameters and this enables binlogging.
In order for our lambda functions to communicate with the database cluster we need to allow hosts inside the security group to connect to it. We can do this by using the cluster's connection property with the allowDefaultPortInternally method.
cluster.connections.allowDefaultPortInternally();
Seeding the Database with a Custom Resource
There are 3 main things we need to do when initializing the database. We need to:
- Set the binlog retention policy
- Add some example data (that will also be stored as binlog events)
- Store the serverId in a
serverId.jsonfile in an S3 Bucket for later use
CDK
Bucket
const binlogBucket = new Bucket(this, `binlog-bucket`, {
removalPolicy: RemovalPolicy.DESTROY,
blockPublicAccess: BlockPublicAccess.BLOCK_ALL,
objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED,
lifecycleRules: [
{
abortIncompleteMultipartUploadAfter: cdk.Duration.days(1),
expiration: cdk.Duration.days(7),
},
],
autoDeleteObjects: true
});
There are a few things I'd like to highlight here:
🔥objectOwnership: ObjectOwnership.BUCKET_OWNER_ENFORCED enforces IAM-based access and ownership for the items in the bucket. I strongly recommend this... it's much better than the "legacy" way that S3 objects are "owned". It avoids cross-account issues and works very smoothly. There's nothing cross-account in this example but this is something I regularly include in all my new buckets now, having been burned by the legacy ownership too many other times.
♻️lifecycleRules enables the bucket to expire items after a certain duration (useful for keeping bucket size in check).
🧹autoDeleteObjects: true... when the stack is destroyed, it will fail deleting the bucket if there are still objects within it. This setting creates a Custom Resource to automatically delete the bucket objects on stack deletion.
Lambda
const tableInitFn = new NodejsFunction(this, `tableInitFn`, {
entry: `${__dirname}/tableInit.ts`,
timeout: Duration.minutes(5),
runtime: Runtime.NODEJS_16_X,
environment: {
SECRET_ARN: cluster.secret!.secretArn,
BUCKET_NAME: binlogBucket.bucketName,
},
logRetention: RetentionDays.ONE_DAY,
vpc,
securityGroups: cluster.connections.securityGroups,
});
Creating the lambda is fairly standard. It's important to note we're putting the lambda in the same VPC as the database, and we're using the cluster's security groups. We're also providing the bucket name and secret ARN via environment properties. Those environment properties become available in the lambda's process.env environment.
🚀 PRO-TIP: When using NodejsFunction make sure you have esbuild installed to your package.json file. Otherwise, CDK will use docker to do your Typescript bundling (which is a lot slower)
Finally, we need to grant read access for the cluster's secret (which was automatically created) and write access to the bucket (for the server id).
cluster.secret!.grantRead(tableInitFn);
binlogBucket.grantWrite(tableInitFn);
Custom Resource
const tableInitProvider = new Provider(this, `tableInitProvider`, {
onEventHandler: tableInitFn,
});
const tableInitResource = new CustomResource(this, `tableInitResource`, {
properties: { Version: "1" },
serviceToken: tableInitProvider.serviceToken,
});
Custom Resources require a Provider that points to the function to be invoked. The Provider is used by the CustomResource itself.
🚀 PRO-TIP: Don't want your CustomResource to run with every deployment? Specify static properties in the CustomResource props. By specifying properties: { Version: "1" } the CustomResource will essentially do a checksum on the properties and only runs when the checksum changes. Want to ensure your CustomResource runs every time? Make a property that is constantly changing (like Date.now())
To make sure that the Custom Resource doesn't accidentally run before the table is done creating we can add a dependency. CDK is supposed to detect this but it doesn't hurt to include an explicit dependency to be absolutely sure:
tableInitResource.node.addDependency(cluster);
Lambda Code
💻 The code for the tableInit.ts lambda is here: github.com/martzcodes/blog-cdk-rds-binlog-s..
We only want the database initialization code to run when the stack is first deployed. Custom Resources have a RequestType passed in to the event that says whether the stack is being Created, Updated, or Deleted. We'll start by checking the RequestType and if it's not Create we'll return a success (so we don't block subsequent deployments).
export const handler = async (
event: CloudFormationCustomResourceEvent
): Promise<
| CloudFormationCustomResourceSuccessResponse
| CloudFormationCustomResourceFailedResponse
> => {
if (event.RequestType === "Create") {
// ... our init code will go here
}
return { ...event, PhysicalResourceId: "retention", Status: "SUCCESS" };
};
Next, we need to run a few SQL commands to:
- Setup binlog retention
- Seed the database
- Select the server id
Setup binlog retention
Earlier we turned on the binlog by setting the binlog_format to ROW. But by default the binlogs aren't retained so Aurora will clean them out. In order to keep them long enough to process we'll set the retention hours to 24 hours.
await connection.query(
"CALL mysql.rds_set_configuration('binlog retention hours', 24);"
);
Seed the database
Now that our binlog is ON and being retained, let's create a table and populate it. Doing so will also create events in the binlog that we can process. For brevity, the code will create a table called tasks insert some rows in individual queries, insert multiple rows in a single query. Update a row and delete a row. The code for this is here.
Select the server id (and store it in S3)
Finally, we'll select the server id and store it in S3. The server id can't be pre-configured via CDK parameters, so we'll store it as a json file so the binlog parse lambda can use it later.
const serverId = await connection.query(`SELECT @@server_id`);
const command = new PutObjectCommand({
Key: "serverId.json",
Bucket: process.env.BUCKET_NAME,
Body: JSON.stringify(serverId[0]),
});
await s3.send(command);
You could also store this in parameter store / a dynamodb table / multiple other means... this is just convenient since the binlog parse lambda already has S3 access.
Creating a Python Lambda to Parse the BinLog in a Typescript Repo
CDK
For this part of the architecture we need to create a Lambda and (optionally) invoke it on a schedule.
Lambda
const binlogFn = new PythonFunction(this, `pybinlog`, {
entry: join(__dirname, "binlog"),
functionName: `pybinlog`,
runtime: Runtime.PYTHON_3_8,
environment: {
SECRET_ARN: cluster.secret!.secretArn,
BUCKET_NAME: binlogBucket.bucketName,
},
memorySize: 4096,
timeout: Duration.minutes(15),
vpc,
securityGroups: cluster.connections.securityGroups,
});
binlogBucket.grantReadWrite(binlogFn);
cluster.secret!.grantRead(binlogFn);
Again, the lambda has access to the VPC and security groups of the cluster and the same general setup as our tableInit lambda. The major difference is we're using a PythonFunction instead of a typescript one.
PythonFunction comes from an experimental CDK 2 module. It uses Docker to package the python code. By placing it in a directory with a requirements.txt file it will automatically install this into the packaged python code zip it up and upload it as the asset for the lambda.
🚨 In practice you would want to create a database user with SELECT, REPLICATION CLIENT, REPLICATION SLAVE grants. You could then use IAM authentication to make requests to the database. For ease, this lambda is making use of the same admin credentials the initialization lambda uses which I am NOT recommending.
ℹ️ I tried many different ways of getting a reliable binlog stream using typescript libraries and failed. I tried https://github.com/nevill/zongji, mysql2 (which didn't actually use the ROW format) and hacking on the normal mysql npm library myself. This python module which the AWS Blog: Streaming Changes in a Database with Amazon Kinesis uses was much faster to get going.
Schedule the Lambda
⚠️ For my actual testing I'm just going to manually invoke the lambda, but if you wanted to schedule the lambda to process the binlog, you could do it like this:
new Rule(this, `Schedule`, {
schedule: Schedule.rate(Duration.minutes(15)),
targets: [new LambdaFunction(binlogFn)]
});
Lambda Code
😅 I haven't touched python since grad school, so if you have any improvements I can make, please let me know on Twitter @martzcodes.
💻 The code for the binlog/index.py (python) lambda is here: github.com/martzcodes/blog-cdk-rds-binlog-s..
The BinLogStreamReader has several inputs that we need to retrieve. First we'll retrieve the cluster's secret with the database host/username/password and then we'll fetch the serverId we stored in S3.
skipToTimestamp = None
get_secret_value_response = secretsmanager.get_secret_value(SecretId=os.environ.get('SECRET_ARN'))
secret_string = get_secret_value_response['SecretString']
db = json.loads(secret_string)
connectionSettings = {
"host": db['host'],
"port": 3306,
"user": db['username'],
"passwd": db['password']
}
get_meta = s3.get_object(Bucket=os.environ.get("BUCKET_NAME"),Key="serverId.json")
server_id = json.loads(get_meta['Body'].read().decode('utf-8'))["@@server_id"]
stream = BinLogStreamReader(
connection_settings=connectionSettings,
server_id=int(server_id),
resume_stream=False,
only_events=[DeleteRowsEvent, WriteRowsEvent, UpdateRowsEvent], # inserts, updates and deletes
only_tables=None, # a list with tables to watch
skip_to_timestamp=skipToTimestamp,
ignored_tables=None, # a list with tables to NOT watch
)
Next we'll initialize some data fields and start looping through the stream. BinLog events are table-specific and then have a list of rows changed for a particular SQL query. When multiple rows are changed in a query they all have the same timestamp.
On subsequent runs, it'll be useful to fetch this timestamp and filter out rows with the same timestamp to ensure we're not re-processing data. I'll go over that more in the next section (Extra Lambda Code).
For now, we initialize our output dictionaries and some generic metrics we're tracking. We'll be storing smaller versions of these row events as JSON in-memory and saving them all to S3 at the end.
totalEventCount = 0
errorCount = 0
dataToStore = {}
dataToStoreCount = {}
dataToStoreLastTimestamp = {}
next_timestamp = None
for binlogevent in stream:
# if skipToTimestamp is enabled this should skip already processed events from the previous run
if binlogevent.timestamp == skipToTimestamp:
continue
if binlogevent.table not in dataToStore:
dataToStore[binlogevent.table] = []
dataToStoreCount[binlogevent.table] = 0
dataToStoreLastTimestamp[binlogevent.table] = 0
for row in binlogevent.rows:
# ... row code here ...
Our final output JSON includes the key(s) for the row changed, the schema, table and event type (Insert, Update, Delete) and then only the changed values if it was an Update and the list of columns that had changed values. If you were to emit this event onto EventBridge you could create Rules with EventPatterns based on any of these fields!
totalEventCount += 1
row_keys = {}
normalized_row = json.loads(json.dumps(row, indent=None, sort_keys=True, default=str, ensure_ascii=False), parse_float=Decimal)
delta = {}
columns_changed = {}
if type(binlogevent).__name__ == "UpdateRowsEvent":
row_keys = primary_keys(binlogevent.primary_key, normalized_row['after_values'])
# the binlog includes all values (changed or not)
# filter down to only the changed values
after = {}
before = {}
for key in normalized_row["after_values"].keys():
if normalized_row["after_values"][key] != normalized_row["before_values"][key]:
after[key] = normalized_row["after_values"][key]
before[key] = normalized_row["before_values"][key]
columns_changed[key] = True
# store them as a string in case we want to store them in dynamodb and avoid type mismatches
delta["after"] = json.dumps(after, indent=None, sort_keys=True, default=str, ensure_ascii=False)
delta["before"] = json.dumps(before, indent=None, sort_keys=True, default=str, ensure_ascii=False)
else:
row_keys = primary_keys(binlogevent.primary_key, normalized_row['values'])
event = {
"keys": row_keys,
"schema": binlogevent.schema,
"table": binlogevent.table,
"type": type(binlogevent).__name__,
}
if type(binlogevent).__name__ == "UpdateRowsEvent":
event["delta"] = delta
event["columnsChanged"] = [col for col in columns_changed]
dataToStore[binlogevent.table].append(event)
dataToStoreCount[binlogevent.table] += 1
dataToStoreLastTimestamp[binlogevent.table] = binlogevent.timestamp
next_timestamp = binlogevent.timestamp
After all of the rows are processed, we store N+2 files to S3:
if next_timestamp:
s3.put_object(
Body=json.dumps({ "lastTimestamps": dataToStoreLastTimestamp, "counts": dataToStoreCount, "tables": dataToStore}, indent=None, sort_keys=True, default=str),
Bucket=os.environ.get("BUCKET_NAME"),
Key="binlog-{}.json".format(str(next_timestamp)))
print("Done with combined file")
for s3Table in dataToStore.keys():
s3.put_object(
Body=json.dumps({ "lastTimestamp": dataToStoreLastTimestamp, "count": dataToStoreCount[s3Table], "events": dataToStore[s3Table]}, indent=None, sort_keys=True, default=str),
Bucket=os.environ.get("BUCKET_NAME"),
Key="{}/table-binlog-{}.json".format(s3Table, str(next_timestamp)))
print("done with individual tables")
s3.put_object(
Body=json.dumps({ "timestamp": next_timestamp, "lastTimestamps": dataToStoreLastTimestamp, "counts": dataToStoreCount }, indent=None, sort_keys=True, default=str),
Bucket=os.environ.get("BUCKET_NAME"),
Key="meta.json")
print("Done with meta file")
We store:
- An "all" file which includes all of our events for all tables.
- N files (1 per table) with only that table's changes.
- A meta file that has the last timestamps
Extra Lambda Code
The BinLogStreamReader library has an input called skip_to_timestamp. This enables you to set a minimum timestamp to process from the binlog(s).
On subsequent runs we could load this file in and use the last timestamp from the previous run:
if os.environ.get('SKIP_TO_TIMESTAMP_ENABLED') == '1':
get_meta = s3.get_object(Bucket=os.environ.get("BUCKET_NAME"),Key="meta.json")
meta_json = json.loads(get_meta['Body'].read().decode('utf-8'))
skipToTimestamp=int(meta_json['timestamp']) # make sure it's an int and not a decimal
print("skipToTimestamp: {} {}".format(skipToTimestamp, type(skipToTimestamp).__name__))
Results
As a "happy accident"... as I was setting up the table init function I accidentally ran it a few times creating extra data. After deploying the code and manually invoking the parser lambda, we get an S3 bucket that looks like this:
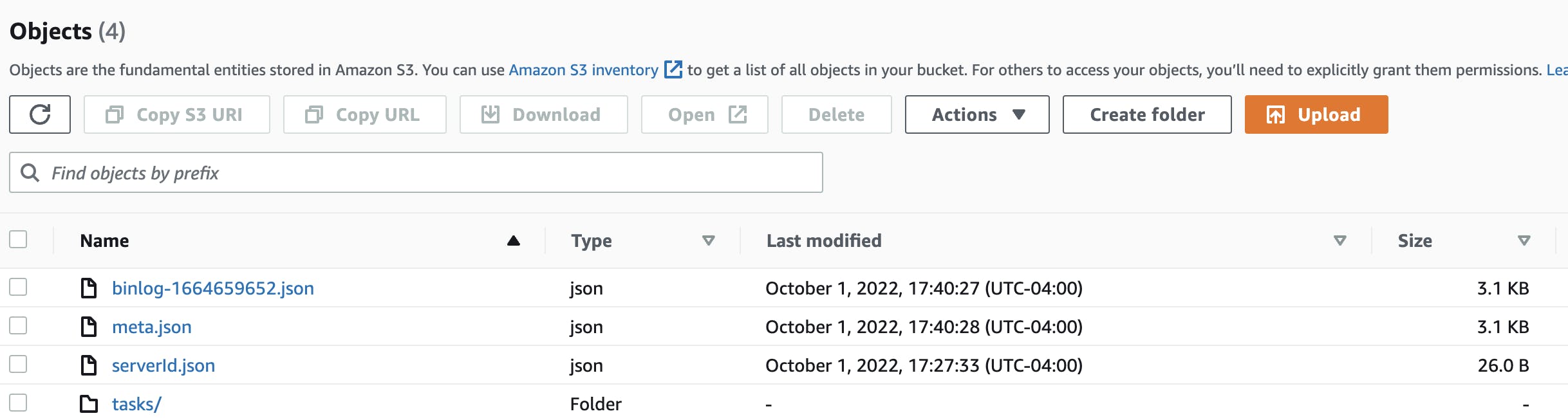
The serverId.json file ends up looking like:
{"@@server_id":1831432894}
The meta.json file looks like:
{
"counts": {
"tasks": 28
},
"lastTimestamps": {
"tasks": 1664659652
},
"timestamp": 1664659652
}
And the tasks/table-binlog-1664659652.json file looks like:
{
"count": 28,
"events": [
{
"keys": {
"task_id": 17
},
"schema": "martzcodes",
"table": "tasks",
"type": "DeleteRowsEvent"
},
{
"keys": {
"task_id": 20
},
"schema": "martzcodes",
"table": "tasks",
"type": "WriteRowsEvent"
},
{
"columnsChanged": ["title"],
"delta": {
"after": "{\"title\": \"Task 2/3\"}",
"before": "{\"title\": \"Task 2/2\"}"
},
"keys": {
"task_id": 19
},
"schema": "martzcodes",
"table": "tasks",
"type": "UpdateRowsEvent"
}
],
"lastTimestamp": {
"tasks": 1664659652
}
}
"Real" World Data
I used a dev database seed to try this out. It processed all >250k database changes across ~200 tables and stored them in a combined “all table” file and individual table-event files in S3 (very similar to the code provided here). This took less than 30 seconds and used very little memory (286MB). We don't necessarily care about change data capture events for ALL of the tables in our database, so it'd be very easy to add lambda S3 triggers on only the tables we care about.
The BinLogStreamReader library also includes options to only process for certain tables and to ignore certain tables.
🚨I did run into an issue with the BinLogStreamReader trying to parse rows with some Unicode characters that it didn't like. It should be possible to get past that issue but it wasn't something I followed through on.
Recap
There are a lot of opportunities here. We can create streams for MySQL similar to DynamoDB streams and drive whole swaths of event driven architecture with it. The BinLogStreamReader library has a lot of flexibility for only focusing on the tables we care about and the ability to do incremental processing.
This would need to be tuned. Lower environments rarely have the same traffic as production environments. An initial deployment of this maybe configured to run more frequently and emit CloudWatch metrics so it could be scaled down later.
For some VERY ROUGH lambda cost calculations... I used a lambda with 4096MB of memory (overkill). If we assume it runs for 1 minute (super overkill) and we invoke a lambda every minute (maybe realistic)...
Lambda with 4096MB running for a minute: $0.004002 / invoke Number of Invokes per month: Appx Minutes per month: 30 x 24 x 60 = 43200 Cost per month (Lambda Invoke Cost x Number of Invokes/month): $172.89 / month
The memory can be scaled down and it certainly shouldn't take a minute to run every minute (especially if you're using skip_to_timestamp, which you would be). In my seed example it processed 250k records in 30 seconds.
🤪IF (big IF) it scales linearly to fit that cost model it would (theoretically) process 30M row changes per hour.
Other questions you should ask yourself:
- Is an X minute delay acceptable?
- How sensitive are you to duplicate-events?
- Do you already have binlogs in place for something else? (in my case, we did so we could piggy-back off of our existing setup with very little overhead 😉)
What other things should you think about when implementing something like this?